 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPiDA: An Easy Plug-in Data Augmentation Framework for High Performance Text Classification
Paper and Code

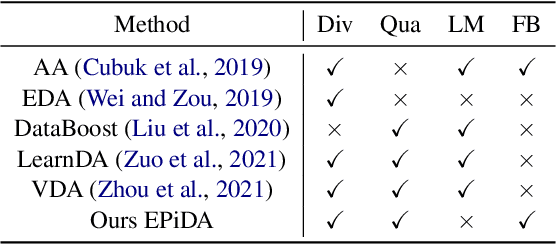

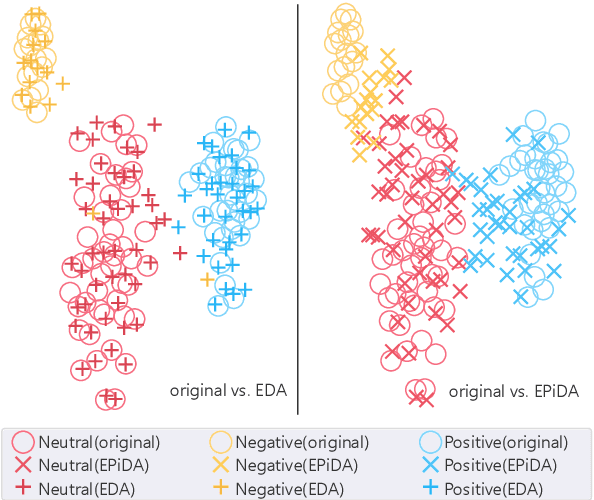
Recent works have empirically shown the effectiveness of data augmentation (DA) in NLP tasks, especially for those suffering from data scarcity. Intuitively, given the size of generated data, their diversity and quality are crucial to the performance of targeted tasks. However, to the best of our knowledge, most existing methods consider only either the diversity or the quality of augmented data, thus cannot fully mine the potential of DA for NLP. In this paper, we present an easy and plug-in data augmentation framework EPiDA to support effective text classification. EPiDA employs two mechanisms: relative entropy maximization (REM) and conditional entropy minimization (CEM) to control data generation, where REM is designed to enhance the diversity of augmented data while CEM is exploited to ensure their semantic consistency. EPiDA can support efficient and continuous data generation for effective classifier training. Extensive experiments show that EPiDA outperforms existing SOTA methods in most cases, though not using any agent networks or pre-trained generation networks, and it works well with various DA algorithms and classification models. Code is available at https://github.com/zhaominyiz/EPiDA.