 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Vision Transformers with Only 2040 Images
Paper and Code
Jan 26, 2022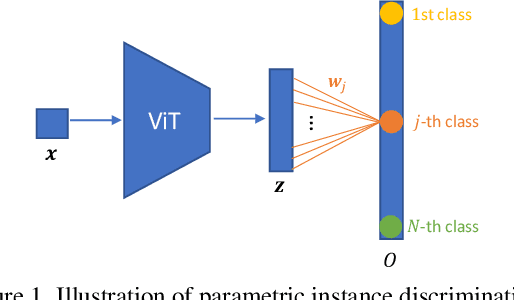
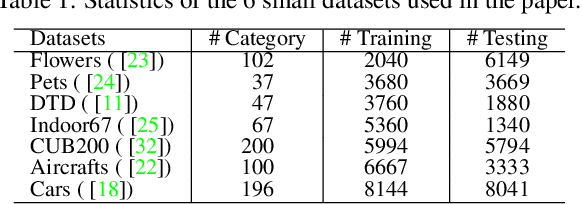
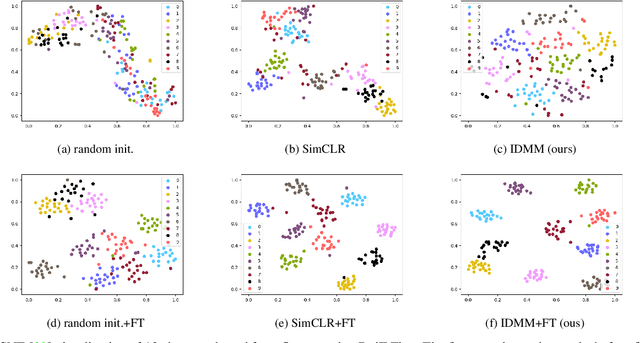
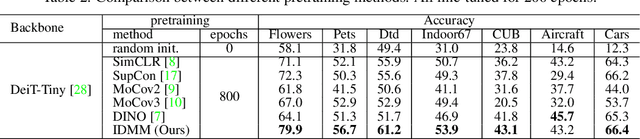
Vision Transformers (ViTs) is emerging as an alternative to convolutional neural networks (CNNs) for visual recognition. They achieve competitive results with CNNs but the lack of the typical convolutional inductive bias makes them more data-hungry than common CNNs. They are often pretrained on JFT-300M or at least ImageNet and few works study training ViTs with limited data. In this paper, we investigate how to train ViTs with limited data (e.g., 2040 images). We give theoretical analyses that our method (based on parametric instance discrimination) is superior to other methods in that it can capture both feature alignment and instance similarities. We achieve state-of-the-art results when training from scratch on 7 small datasets under various ViT backbones. We also investigate the transferring ability of small datasets and find that representations learned from small datasets can even improve large-scale ImageNet training.