 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorst Case Matters for Few-Shot Recognition
Paper and Code
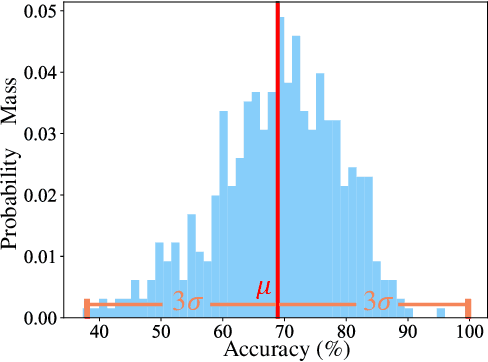
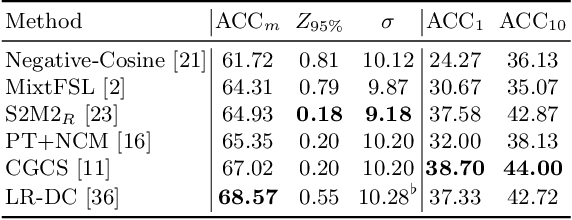
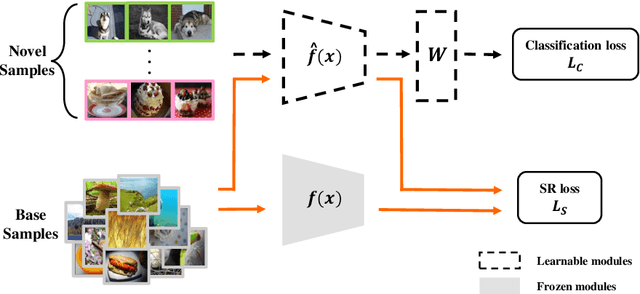
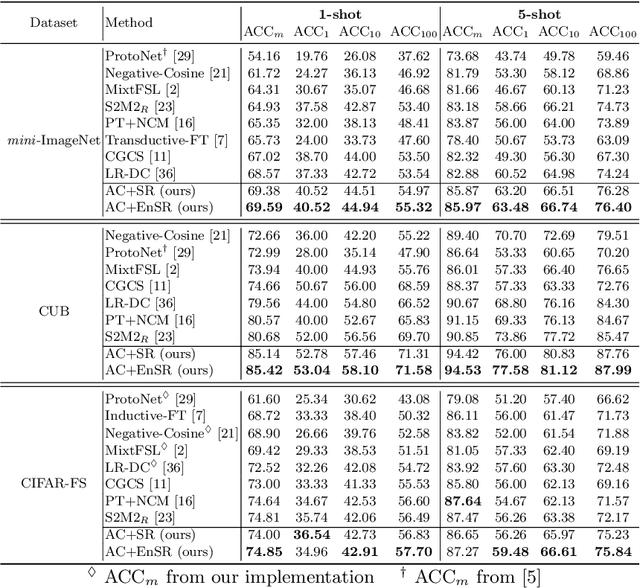
Few-shot recognition learns a recognition model with very few (e.g., 1 or 5) images per category, and current few-shot learning methods focus on improving the average accuracy over many episodes. We argue that in real-world applications we may often only try one episode instead of many, and hence maximizing the worst-case accuracy is more important than maximizing the average accuracy. We empirically show that a high average accuracy not necessarily means a high worst-case accuracy. Since this objective is not accessible, we propose to reduce the standard deviation and increase the average accuracy simultaneously. In turn, we devise two strategies from the bias-variance tradeoff perspective to implicitly reach this goal: a simple yet effective stability regularization (SR) loss together with model ensemble to reduce variance during fine-tuning, and an adaptability calibration mechanism to reduce the bias. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed strategies, which outperforms current state-of-the-art methods with a significant margin in terms of not only average, but also worst-case accuracy.