 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
Collaboration of Teachers for Semi-supervised Object Detection
May 22, 2024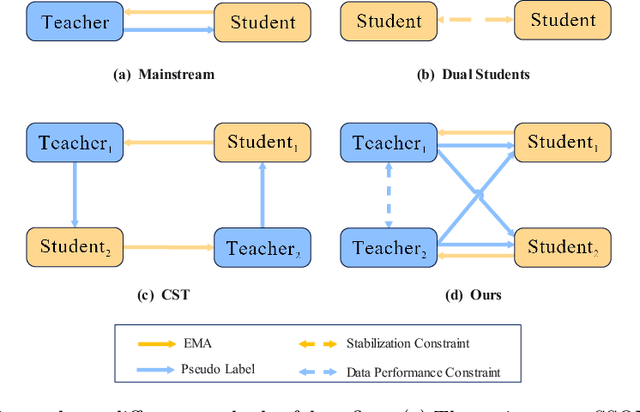
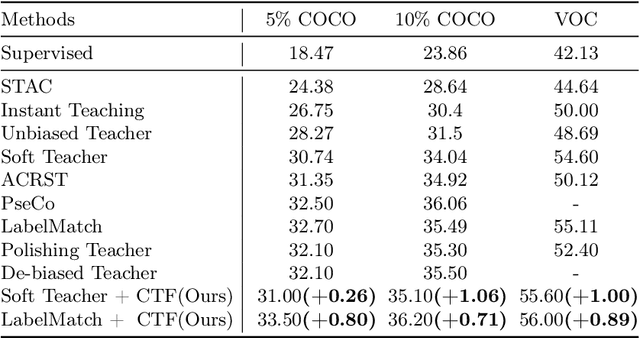

Recent semi-supervised object detection (SSOD) has achieved remarkable progress by leveraging unlabeled data for training. Mainstream SSOD methods rely on Consistency Regularization methods and Exponential Moving Average (EMA), which form a cyclic data flow. However, the EMA updating training approach leads to weight coupling between the teacher and student models. This coupling in a cyclic data flow results in a decrease in the utilization of unlabeled data information and the confirmation bias on low-quality or erroneous pseudo-labels. To address these issues, we propose the Collaboration of Teachers Framework (CTF), which consists of multiple pairs of teacher and student models for training. In the learning process of CTF, the Data Performance Consistency Optimization module (DPCO) informs the best pair of teacher models possessing the optimal pseudo-labels during the past training process, and these most reliable pseudo-labels generated by the best performing teacher would guide the other student models. As a consequence, this framework greatly improves the utilization of unlabeled data and prevents the positive feedback cycle of unreliable pseudo-labels. The CTF achieves outstanding results on numerous SSOD datasets, including a 0.71% mAP improvement on the 10% annotated COCO dataset and a 0.89% mAP improvement on the VOC dataset compared to LabelMatch and converges significantly faster. Moreover, the CTF is plug-and-play and can be integrated with other mainstream SSOD methods.