 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPT-V2: Efficient Image Processing Transformer using Hierarchical Attentions
Paper and Code
Mar 31, 2024
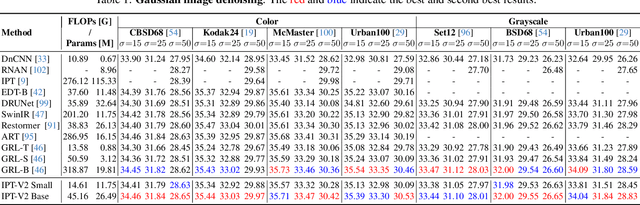
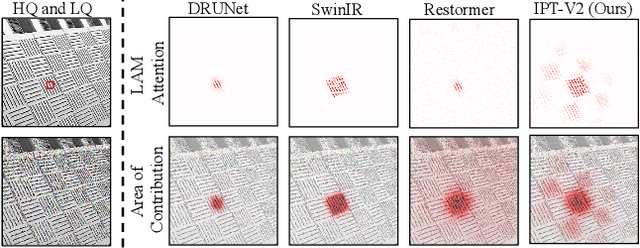

Recent advances have demonstrated the powerful capability of transformer architecture in image restoration. However, our analysis indicates that existing transformerbased methods can not establish both exact global and local dependencies simultaneously, which are much critical to restore the details and missing content of degraded images. To this end, we present an efficient image processing transformer architecture with hierarchical attentions, called IPTV2, adopting a focal context self-attention (FCSA) and a global grid self-attention (GGSA) to obtain adequate token interactions in local and global receptive fields. Specifically, FCSA applies the shifted window mechanism into the channel self-attention, helps capture the local context and mutual interaction across channels. And GGSA constructs long-range dependencies in the cross-window grid, aggregates global information in spatial dimension. Moreover, we introduce structural re-parameterization technique to feed-forward network to further improve the model capability. Extensive experiments demonstrate that our proposed IPT-V2 achieves state-of-the-art results on various image processing tasks, covering denoising, deblurring, deraining and obtains much better trade-off for performance and computational complexity than previous methods. Besides, we extend our method to image generation as latent diffusion backbone, and significantly outperforms DiTs.