 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Generative and Discriminative Models for Unified Visual Perception with Diffusion Priors
Jan 29, 2024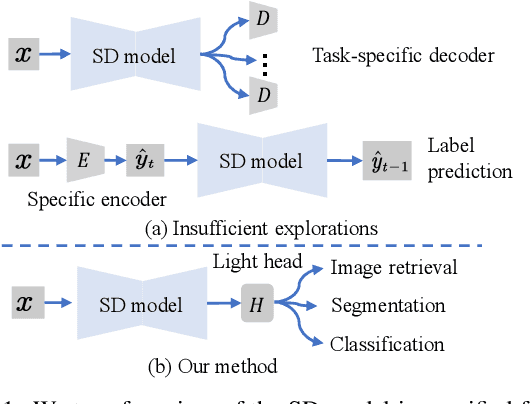
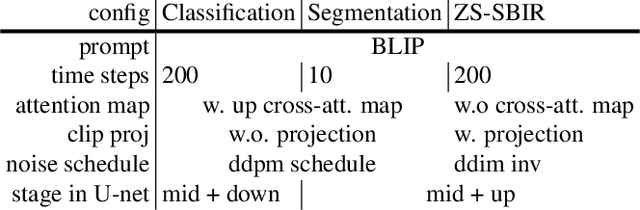
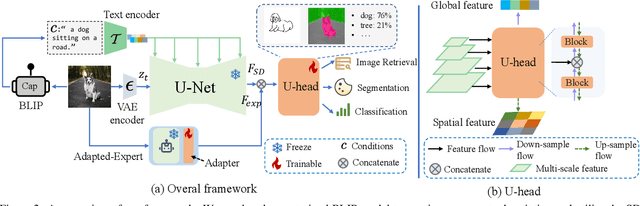
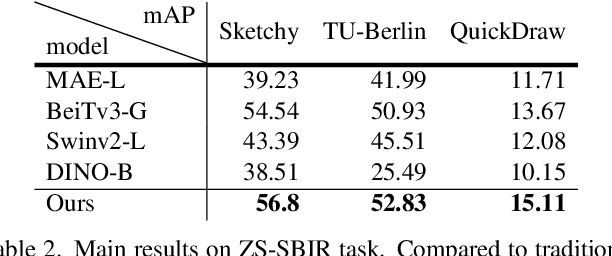
The remarkable prowess of diffusion models in image generation has spurred efforts to extend their application beyond generative tasks. However, a persistent challenge exists in lacking a unified approach to apply diffusion models to visual perception tasks with diverse semantic granularity requirements. Our purpose is to establish a unified visual perception framework, capitalizing on the potential synergies between generative and discriminative models. In this paper, we propose Vermouth, a simple yet effective framework comprising a pre-trained Stable Diffusion (SD) model containing rich generative priors, a unified head (U-head) capable of integrating hierarchical representations, and an adapted expert providing discriminative priors. Comprehensive investigations unveil potential characteristics of Vermouth, such as varying granularity of perception concealed in latent variables at distinct time steps and various U-net stages. We emphasize that there is no necessity for incorporating a heavyweight or intricate decoder to transform diffusion models into potent representation learners. Extensive comparative evaluations against tailored discriminative models showcase the efficacy of our approach on zero-shot sketch-based image retrieval (ZS-SBIR), few-shot classification, and open-vocabulary semantic segmentation tasks. The promising results demonstrate the potential of diffusion models as formidable learners, establishing their significance in furnishing informative and robust visual representations.
CatVersion: Concatenating Embeddings for Diffusion-Based Text-to-Image Personalization
Nov 30, 2023
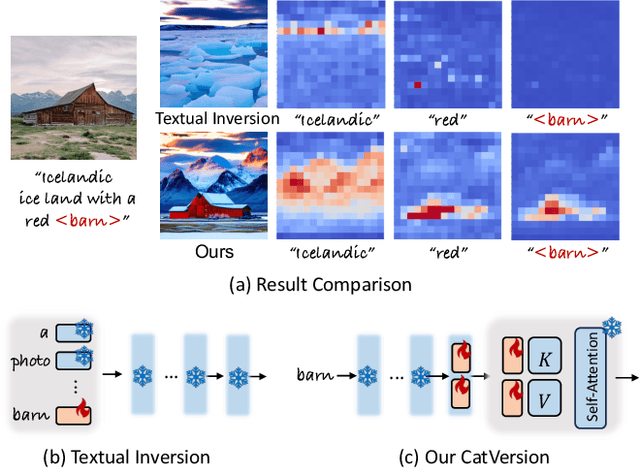
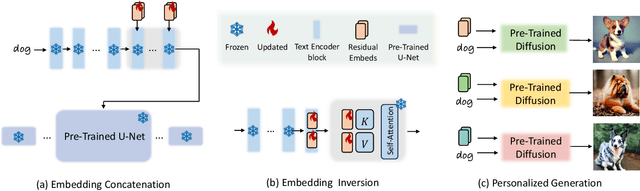
We propose CatVersion, an inversion-based method that learns the personalized concept through a handful of examples. Subsequently, users can utilize text prompts to generate images that embody the personalized concept, thereby achieving text-to-image personalization. In contrast to existing approaches that emphasize word embedding learning or parameter fine-tuning for the diffusion model, which potentially causes concept dilution or overfitting, our method concatenates embeddings on the feature-dense space of the text encoder in the diffusion model to learn the gap between the personalized concept and its base class, aiming to maximize the preservation of prior knowledge in diffusion models while restoring the personalized concepts. To this end, we first dissect the text encoder's integration in the image generation process to identify the feature-dense space of the encoder. Afterward, we concatenate embeddings on the Keys and Values in this space to learn the gap between the personalized concept and its base class. In this way, the concatenated embeddings ultimately manifest as a residual on the original attention output. To more accurately and unbiasedly quantify the results of personalized image generation, we improve the CLIP image alignment score based on masks. Qualitatively and quantitatively, CatVersion helps to restore personalization concepts more faithfully and enables more robust editing.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023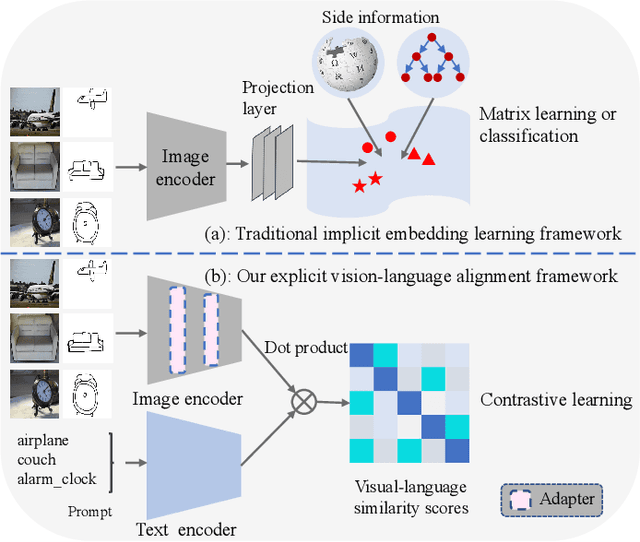
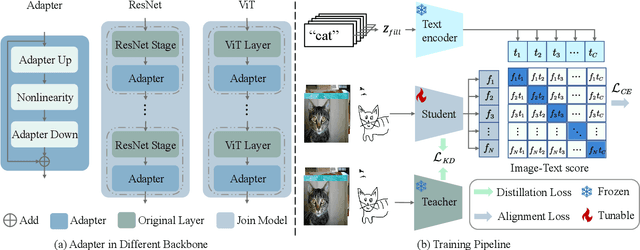
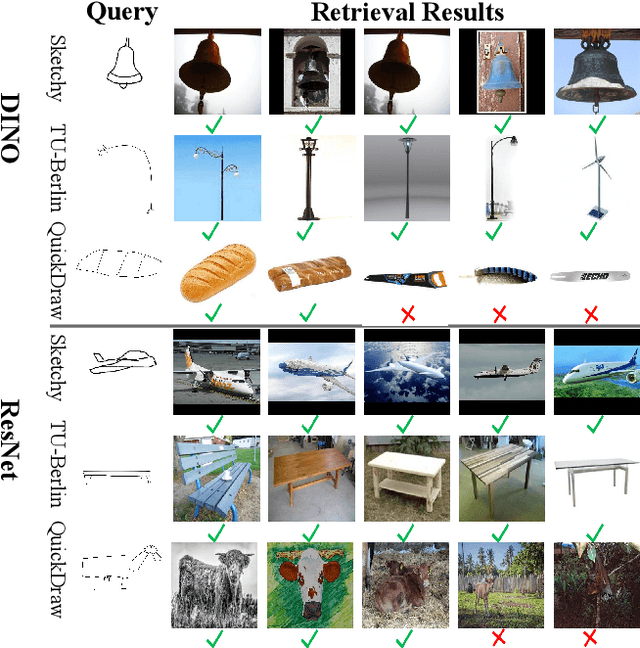
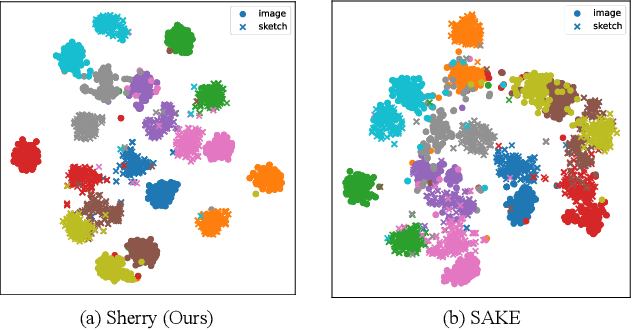
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.