 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Viewpoint: Robust 3D Object Recognition under Arbitrary Views through Joint Multi-Part Representation
Jul 04, 2024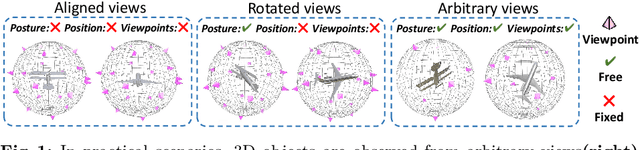
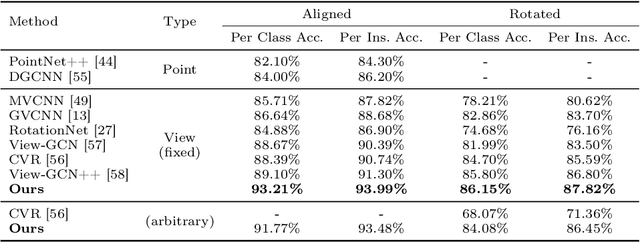
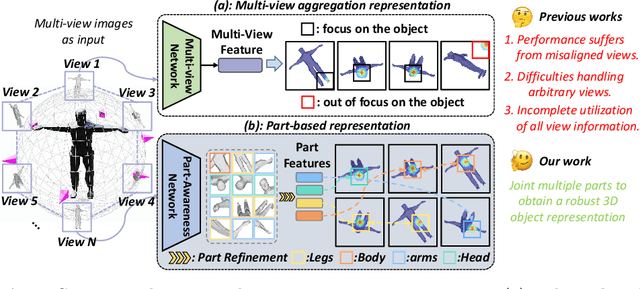
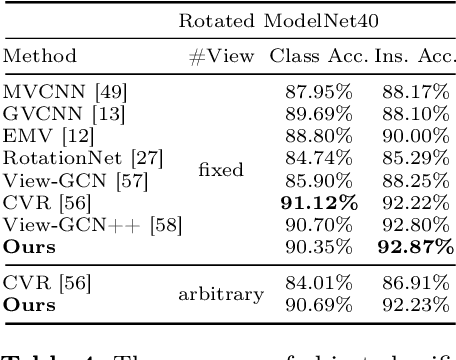
Existing view-based methods excel at recognizing 3D objects from predefined viewpoints, but their exploration of recognition under arbitrary views is limited. This is a challenging and realistic setting because each object has different viewpoint positions and quantities, and their poses are not aligned. However, most view-based methods, which aggregate multiple view features to obtain a global feature representation, hard to address 3D object recognition under arbitrary views. Due to the unaligned inputs from arbitrary views, it is challenging to robustly aggregate features, leading to performance degradation. In this paper, we introduce a novel Part-aware Network (PANet), which is a part-based representation, to address these issues. This part-based representation aims to localize and understand different parts of 3D objects, such as airplane wings and tails. It has properties such as viewpoint invariance and rotation robustness, which give it an advantage in addressing the 3D object recognition problem under arbitrary views. Our results on benchmark datasets clearly demonstrate that our proposed method outperforms existing view-based aggregation baselines for the task of 3D object recognition under arbitrary views, even surpassing most fixed viewpoint methods.
Tuning-Free Adaptive Style Incorporation for Structure-Consistent Text-Driven Style Transfer
Apr 10, 2024

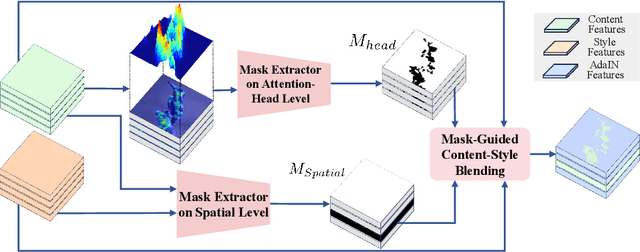

In this work, we target the task of text-driven style transfer in the context of text-to-image (T2I) diffusion models. The main challenge is consistent structure preservation while enabling effective style transfer effects. The past approaches in this field directly concatenate the content and style prompts for a prompt-level style injection, leading to unavoidable structure distortions. In this work, we propose a novel solution to the text-driven style transfer task, namely, Adaptive Style Incorporation~(ASI), to achieve fine-grained feature-level style incorporation. It consists of the Siamese Cross-Attention~(SiCA) to decouple the single-track cross-attention to a dual-track structure to obtain separate content and style features, and the Adaptive Content-Style Blending (AdaBlending) module to couple the content and style information from a structure-consistent manner. Experimentally, our method exhibits much better performance in both structure preservation and stylized effects.
SSR: SAM is a Strong Regularizer for domain adaptive semantic segmentation
Jan 26, 2024


We introduced SSR, which utilizes SAM (segment-anything) as a strong regularizer during training, to greatly enhance the robustness of the image encoder for handling various domains. Specifically, given the fact that SAM is pre-trained with a large number of images over the internet, which cover a diverse variety of domains, the feature encoding extracted by the SAM is obviously less dependent on specific domains when compared to the traditional ImageNet pre-trained image encoder. Meanwhile, the ImageNet pre-trained image encoder is still a mature choice of backbone for the semantic segmentation task, especially when the SAM is category-irrelevant. As a result, our SSR provides a simple yet highly effective design. It uses the ImageNet pre-trained image encoder as the backbone, and the intermediate feature of each stage (ie there are 4 stages in MiT-B5) is regularized by SAM during training. After extensive experimentation on GTA5$\rightarrow$Cityscapes, our SSR significantly improved performance over the baseline without introducing any extra inference overhead.
Beyond Prototypes: Semantic Anchor Regularization for Better Representation Learning
Dec 19, 2023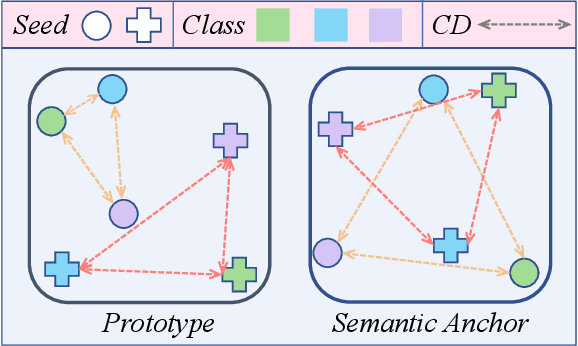
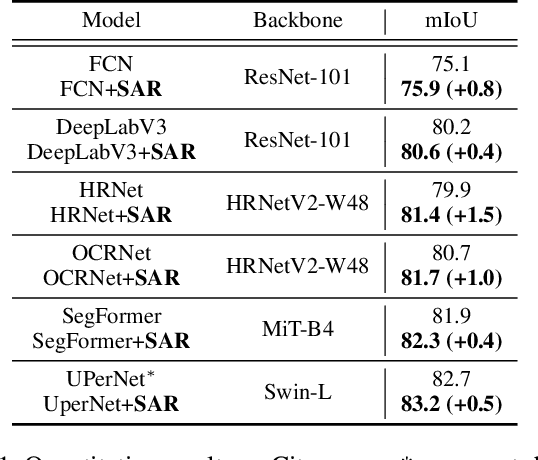
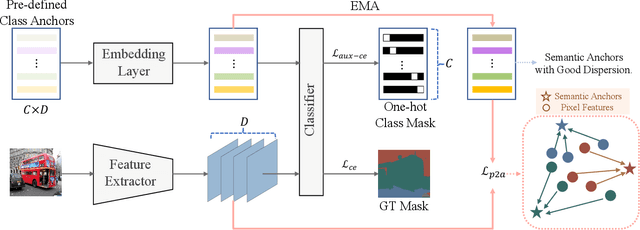
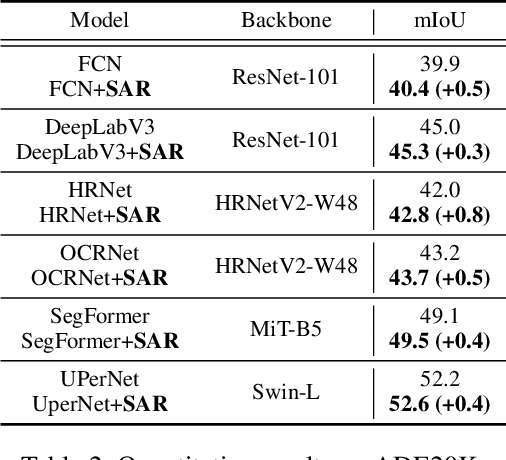
One of the ultimate goals of representation learning is to achieve compactness within a class and well-separability between classes. Many outstanding metric-based and prototype-based methods following the Expectation-Maximization paradigm, have been proposed for this objective. However, they inevitably introduce biases into the learning process, particularly with long-tail distributed training data. In this paper, we reveal that the class prototype is not necessarily to be derived from training features and propose a novel perspective to use pre-defined class anchors serving as feature centroid to unidirectionally guide feature learning. However, the pre-defined anchors may have a large semantic distance from the pixel features, which prevents them from being directly applied. To address this issue and generate feature centroid independent from feature learning, a simple yet effective Semantic Anchor Regularization (SAR) is proposed. SAR ensures the interclass separability of semantic anchors in the semantic space by employing a classifier-aware auxiliary cross-entropy loss during training via disentanglement learning. By pulling the learned features to these semantic anchors, several advantages can be attained: 1) the intra-class compactness and naturally inter-class separability, 2) induced bias or errors from feature learning can be avoided, and 3) robustness to the long-tailed problem. The proposed SAR can be used in a plug-and-play manner in the existing models. Extensive experiments demonstrate that the SAR performs better than previous sophisticated prototype-based methods. The implementation is available at https://github.com/geyanqi/SAR.