 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Descendant Face Synthesis
Paper and Code
Feb 26, 2020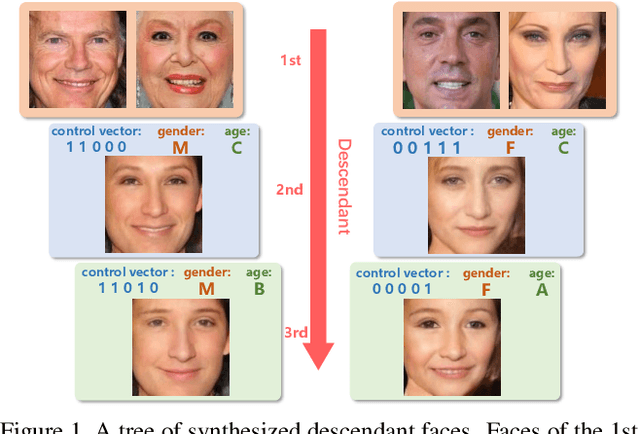
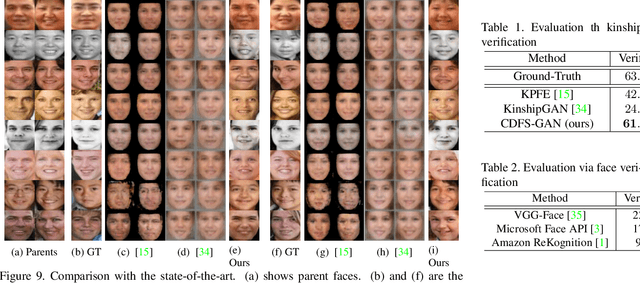


Kinship face synthesis is an interesting topic raised to answer questions like "what will your future children look like?". Published approaches to this topic are limited. Most of the existing methods train models for one-versus-one kin relation, which only consider one parent face and one child face by directly using an auto-encoder without any explicit control over the resemblance of the synthesized face to the parent face. In this paper, we propose a novel method for controllable descendant face synthesis, which models two-versus-one kin relation between two parent faces and one child face. Our model consists of an inheritance module and an attribute enhancement module, where the former is designed for accurate control over the resemblance between the synthesized face and parent faces, and the latter is designed for control over age and gender. As there is no large scale database with father-mother-child kinship annotation, we propose an effective strategy to train the model without using the ground truth descendant faces. No carefully designed image pairs are required for learning except only age and gender labels of training faces. We conduct comprehensive experimental evaluations on three public benchmark databases, which demonstrates encouraging results.