 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyePCR: A Comprehensive Benchmark for Fine-Grained Perception, Knowledge Comprehension and Clinical Reasoning in Ophthalmic Surgery
Sep 19, 2025MLLMs (Multimodal Large Language Models) have showcased remarkable capabilities, but their performance in high-stakes, domain-specific scenarios like surgical settings, remains largely under-explored. To address this gap, we develop \textbf{EyePCR}, a large-scale benchmark for ophthalmic surgery analysis, grounded in structured clinical knowledge to evaluate cognition across \textit{Perception}, \textit{Comprehension} and \textit{Reasoning}. EyePCR offers a richly annotated corpus with more than 210k VQAs, which cover 1048 fine-grained attributes for multi-view perception, medical knowledge graph of more than 25k triplets for comprehension, and four clinically grounded reasoning tasks. The rich annotations facilitate in-depth cognitive analysis, simulating how surgeons perceive visual cues and combine them with domain knowledge to make decisions, thus greatly improving models' cognitive ability. In particular, \textbf{EyePCR-MLLM}, a domain-adapted variant of Qwen2.5-VL-7B, achieves the highest accuracy on MCQs for \textit{Perception} among compared models and outperforms open-source models in \textit{Comprehension} and \textit{Reasoning}, rivalling commercial models like GPT-4.1. EyePCR reveals the limitations of existing MLLMs in surgical cognition and lays the foundation for benchmarking and enhancing clinical reliability of surgical video understanding models.
{S$^3$-Mamba}: Small-Size-Sensitive Mamba for Lesion Segmentation
Dec 19, 2024Small lesions play a critical role in early disease diagnosis and intervention of severe infections. Popular models often face challenges in segmenting small lesions, as it occupies only a minor portion of an image, while down\_sampling operations may inevitably lose focus on local features of small lesions. To tackle the challenges, we propose a {\bf S}mall-{\bf S}ize-{\bf S}ensitive {\bf Mamba} ({\bf S$^3$-Mamba}), which promotes the sensitivity to small lesions across three dimensions: channel, spatial, and training strategy. Specifically, an Enhanced Visual State Space block is designed to focus on small lesions through multiple residual connections to preserve local features, and selectively amplify important details while suppressing irrelevant ones through channel-wise attention. A Tensor-based Cross-feature Multi-scale Attention is designed to integrate input image features and intermediate-layer features with edge features and exploit the attentive support of features across multiple scales, thereby retaining spatial details of small lesions at various granularities. Finally, we introduce a novel regularized curriculum learning to automatically assess lesion size and sample difficulty, and gradually focus from easy samples to hard ones like small lesions. Extensive experiments on three medical image segmentation datasets show the superiority of our S$^3$-Mamba, especially in segmenting small lesions. Our code is available at https://github.com/ErinWang2023/S3-Mamba.
Facial Expression Recognition Using a Hybrid CNN-SIFT Aggregator
Aug 12, 2017


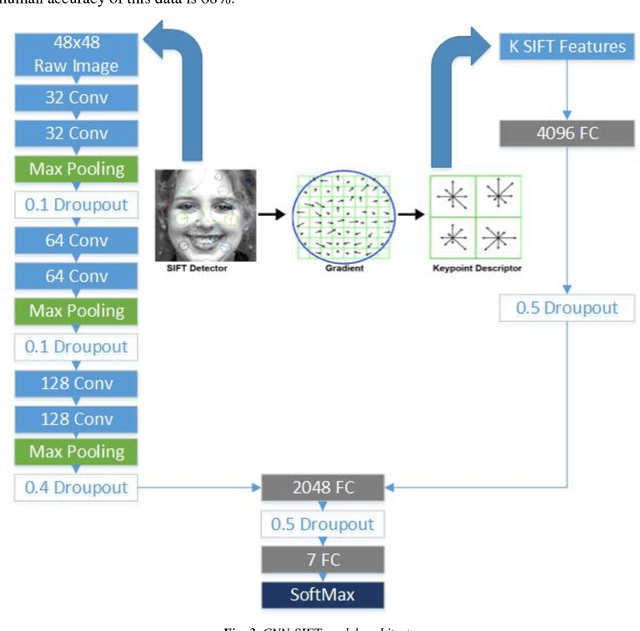
Deriving an effective facial expression recognition component is important for a successful human-computer interaction system. Nonetheless, recognizing facial expression remains a challenging task. This paper describes a novel approach towards facial expression recognition task. The proposed method is motivated by the success of Convolutional Neural Networks (CNN) on the face recognition problem. Unlike other works, we focus on achieving good accuracy while requiring only a small sample data for training. Scale Invariant Feature Transform (SIFT) features are used to increase the performance on small data as SIFT does not require extensive training data to generate useful features. In this paper, both Dense SIFT and regular SIFT are studied and compared when merged with CNN features. Moreover, an aggregator of the models is developed. The proposed approach is tested on the FER-2013 and CK+ datasets. Results demonstrate the superiority of CNN with Dense SIFT over conventional CNN and CNN with SIFT. The accuracy even increased when all the models are aggregated which generates state-of-art results on FER-2013 and CK+ datasets, where it achieved 73.4% on FER-2013 and 99.1% on CK+.