 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Pseudo Modality Generation for Incomplete Multi-Modal MRI Reconstruction
Aug 20, 2023While multi-modal learning has been widely used for MRI reconstruction, it relies on paired multi-modal data which is difficult to acquire in real clinical scenarios. Especially in the federated setting, the common situation is that several medical institutions only have single-modal data, termed the modality missing issue. Therefore, it is infeasible to deploy a standard federated learning framework in such conditions. In this paper, we propose a novel communication-efficient federated learning framework, namely Fed-PMG, to address the missing modality challenge in federated multi-modal MRI reconstruction. Specifically, we utilize a pseudo modality generation mechanism to recover the missing modality for each single-modal client by sharing the distribution information of the amplitude spectrum in frequency space. However, the step of sharing the original amplitude spectrum leads to heavy communication costs. To reduce the communication cost, we introduce a clustering scheme to project the set of amplitude spectrum into finite cluster centroids, and share them among the clients. With such an elaborate design, our approach can effectively complete the missing modality within an acceptable communication cost. Extensive experiments demonstrate that our proposed method can attain similar performance with the ideal scenario, i.e., all clients have the full set of modalities. The source code will be released.
Rethinking Client Drift in Federated Learning: A Logit Perspective
Aug 20, 2023Federated Learning (FL) enables multiple clients to collaboratively learn in a distributed way, allowing for privacy protection. However, the real-world non-IID data will lead to client drift which degrades the performance of FL. Interestingly, we find that the difference in logits between the local and global models increases as the model is continuously updated, thus seriously deteriorating FL performance. This is mainly due to catastrophic forgetting caused by data heterogeneity between clients. To alleviate this problem, we propose a new algorithm, named FedCSD, a Class prototype Similarity Distillation in a federated framework to align the local and global models. FedCSD does not simply transfer global knowledge to local clients, as an undertrained global model cannot provide reliable knowledge, i.e., class similarity information, and its wrong soft labels will mislead the optimization of local models. Concretely, FedCSD introduces a class prototype similarity distillation to align the local logits with the refined global logits that are weighted by the similarity between local logits and the global prototype. To enhance the quality of global logits, FedCSD adopts an adaptive mask to filter out the terrible soft labels of the global models, thereby preventing them to mislead local optimization. Extensive experiments demonstrate the superiority of our method over the state-of-the-art federated learning approaches in various heterogeneous settings. The source code will be released.
A Simple Data Augmentation for Feature Distribution Skewed Federated Learning
Jun 14, 2023Federated learning (FL) facilitates collaborative learning among multiple clients in a distributed manner, while ensuring privacy protection. However, its performance is inevitably degraded as suffering data heterogeneity, i.e., non-IID data. In this paper, we focus on the feature distribution skewed FL scenario, which is widespread in real-world applications. The main challenge lies in the feature shift caused by the different underlying distributions of local datasets. While the previous attempts achieved progress, few studies pay attention to the data itself, the root of this issue. Therefore, the primary goal of this paper is to develop a general data augmentation technique at the input level, to mitigate the feature shift. To achieve this goal, we propose FedRDN, a simple yet remarkably effective data augmentation method for feature distribution skewed FL, which randomly injects the statistics of the dataset from the entire federation into the client's data. By this, our method can effectively improve the generalization of features, thereby mitigating the feature shift. Moreover, FedRDN is a plug-and-play component, which can be seamlessly integrated into the data augmentation flow with only a few lines of code. Extensive experiments on several datasets show that the performance of various representative FL works can be further improved by combining them with FedRDN, which demonstrates the strong scalability and generalizability of FedRDN. The source code will be released.
Cross-Modal Vertical Federated Learning for MRI Reconstruction
Jun 05, 2023Federated learning enables multiple hospitals to cooperatively learn a shared model without privacy disclosure. Existing methods often take a common assumption that the data from different hospitals have the same modalities. However, such a setting is difficult to fully satisfy in practical applications, since the imaging guidelines may be different between hospitals, which makes the number of individuals with the same set of modalities limited. To this end, we formulate this practical-yet-challenging cross-modal vertical federated learning task, in which shape data from multiple hospitals have different modalities with a small amount of multi-modality data collected from the same individuals. To tackle such a situation, we develop a novel framework, namely Federated Consistent Regularization constrained Feature Disentanglement (Fed-CRFD), for boosting MRI reconstruction by effectively exploring the overlapping samples (individuals with multi-modalities) and solving the domain shift problem caused by different modalities. Particularly, our Fed-CRFD involves an intra-client feature disentangle scheme to decouple data into modality-invariant and modality-specific features, where the modality-invariant features are leveraged to mitigate the domain shift problem. In addition, a cross-client latent representation consistency constraint is proposed specifically for the overlapping samples to further align the modality-invariant features extracted from different modalities. Hence, our method can fully exploit the multi-source data from hospitals while alleviating the domain shift problem. Extensive experiments on two typical MRI datasets demonstrate that our network clearly outperforms state-of-the-art MRI reconstruction methods. The source code will be publicly released upon the publication of this work.
Specificity-Preserving Federated Learning for MR Image Reconstruction
Dec 09, 2021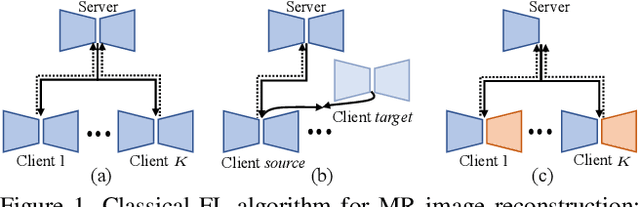

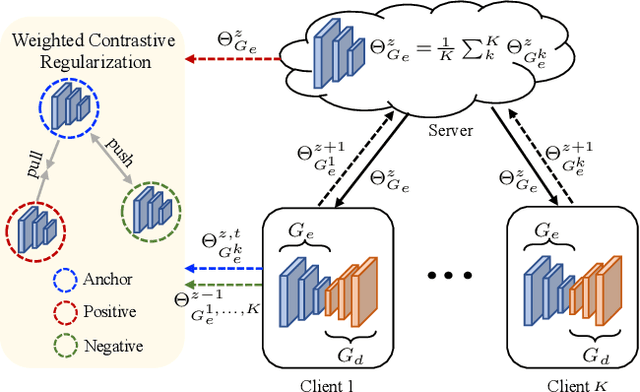
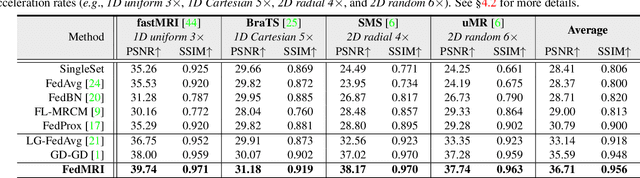
Federated learning (FL) can be used to improve data privacy and efficiency in magnetic resonance (MR) image reconstruction by enabling multiple institutions to collaborate without needing to aggregate local data. However, the domain shift caused by different MR imaging protocols can substantially degrade the performance of FL models. Recent FL techniques tend to solve this by enhancing the generalization of the global model, but they ignore the domain-specific features, which may contain important information about the device properties and be useful for local reconstruction. In this paper, we propose a specificity-preserving FL algorithm for MR image reconstruction (FedMRI). The core idea is to divide the MR reconstruction model into two parts: a globally shared encoder to obtain a generalized representation at the global level, and a client-specific decoder to preserve the domain-specific properties of each client, which is important for collaborative reconstruction when the clients have unique distribution. Moreover, to further boost the convergence of the globally shared encoder when a domain shift is present, a weighted contrastive regularization is introduced to directly correct any deviation between the client and server during optimization. Extensive experiments demonstrate that our FedMRI's reconstructed results are the closest to the ground-truth for multi-institutional data, and that it outperforms state-of-the-art FL methods.
Exploring Separable Attention for Multi-Contrast MR Image Super-Resolution
Sep 03, 2021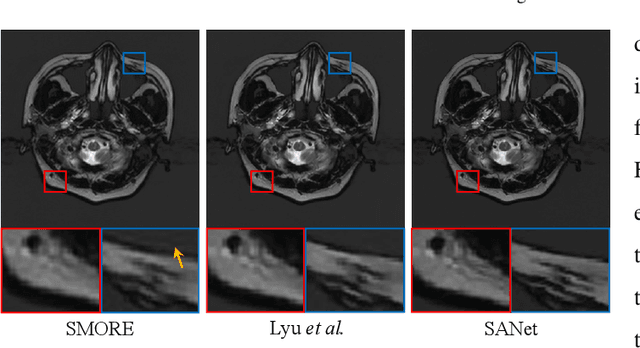
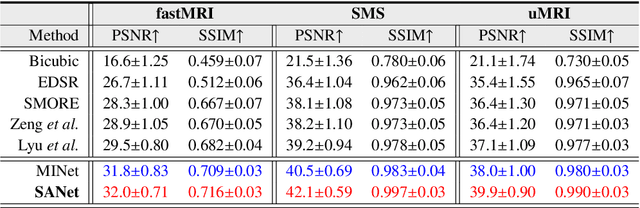


Super-resolving the Magnetic Resonance (MR) image of a target contrast under the guidance of the corresponding auxiliary contrast, which provides additional anatomical information, is a new and effective solution for fast MR imaging. However, current multi-contrast super-resolution (SR) methods tend to concatenate different contrasts directly, ignoring their relationships in different clues, \eg, in the foreground and background. In this paper, we propose a separable attention network (comprising a foreground priority attention and background separation attention), named SANet. Our method can explore the foreground and background areas in the forward and reverse directions with the help of the auxiliary contrast, enabling it to learn clearer anatomical structures and edge information for the SR of a target-contrast MR image. SANet provides three appealing benefits: (1) It is the first model to explore a separable attention mechanism that uses the auxiliary contrast to predict the foreground and background regions, diverting more attention to refining any uncertain details between these regions and correcting the fine areas in the reconstructed results. (2) A multi-stage integration module is proposed to learn the response of multi-contrast fusion at different stages, obtain the dependency between the fused features, and improve their representation ability. (3) Extensive experiments with various state-of-the-art multi-contrast SR methods on fastMRI and clinical \textit{in vivo} datasets demonstrate the superiority of our model.
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution
Jul 05, 2021
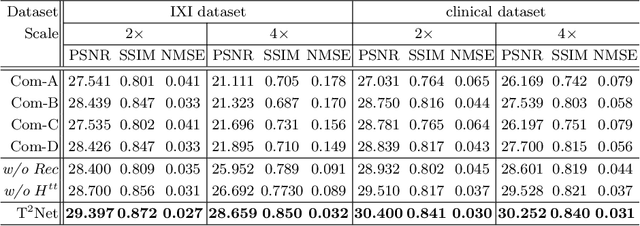

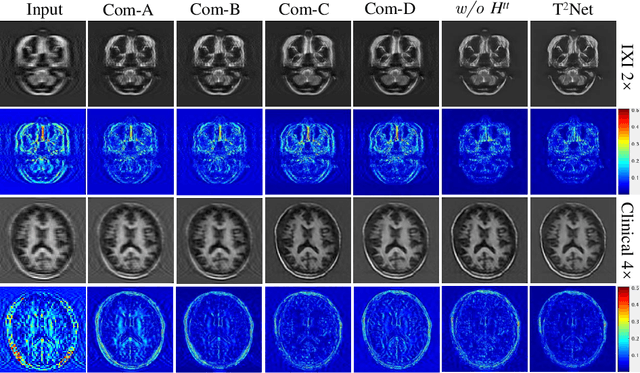
The core problem of Magnetic Resonance Imaging (MRI) is the trade off between acceleration and image quality. Image reconstruction and super-resolution are two crucial techniques in Magnetic Resonance Imaging (MRI). Current methods are designed to perform these tasks separately, ignoring the correlations between them. In this work, we propose an end-to-end task transformer network (T$^2$Net) for joint MRI reconstruction and super-resolution, which allows representations and feature transmission to be shared between multiple task to achieve higher-quality, super-resolved and motion-artifacts-free images from highly undersampled and degenerated MRI data. Our framework combines both reconstruction and super-resolution, divided into two sub-branches, whose features are expressed as queries and keys. Specifically, we encourage joint feature learning between the two tasks, thereby transferring accurate task information. We first use two separate CNN branches to extract task-specific features. Then, a task transformer module is designed to embed and synthesize the relevance between the two tasks. Experimental results show that our multi-task model significantly outperforms advanced sequential methods, both quantitatively and qualitatively.
Accelerated Multi-Modal MR Imaging with Transformers
Jun 29, 2021
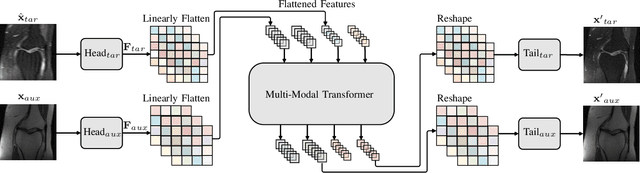


Accelerating multi-modal magnetic resonance (MR) imaging is a new and effective solution for fast MR imaging, providing superior performance in restoring the target modality from its undersampled counterpart with guidance from an auxiliary modality. However, existing works simply introduce the auxiliary modality as prior information, lacking in-depth investigations on the potential mechanisms for fusing two modalities. Further, they usually rely on the convolutional neural networks (CNNs), which focus on local information and prevent them from fully capturing the long-distance dependencies of global knowledge. To this end, we propose a multi-modal transformer (MTrans), which is capable of transferring multi-scale features from the target modality to the auxiliary modality, for accelerated MR imaging. By restructuring the transformer architecture, our MTrans gains a powerful ability to capture deep multi-modal information. More specifically, the target modality and the auxiliary modality are first split into two branches and then fused using a multi-modal transformer module. This module is based on an improved multi-head attention mechanism, named the cross attention module, which absorbs features from the auxiliary modality that contribute to the target modality. Our framework provides two appealing benefits: (i) MTrans is the first attempt at using improved transformers for multi-modal MR imaging, affording more global information compared with CNN-based methods. (ii) A new cross attention module is proposed to exploit the useful information in each branch at different scales. It affords both distinct structural information and subtle pixel-level information, which supplement the target modality effectively.