 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoHead: Emotional Talking Head via Manipulating Semantic Expression Parameters
Mar 25, 2025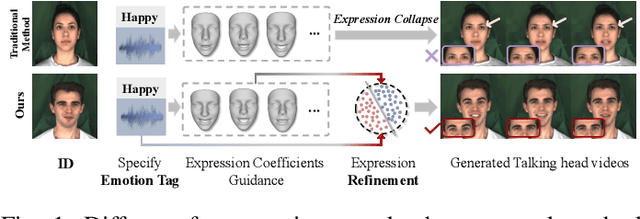
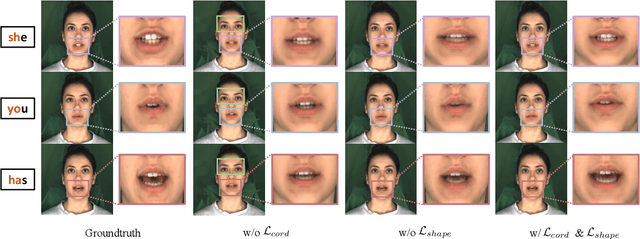

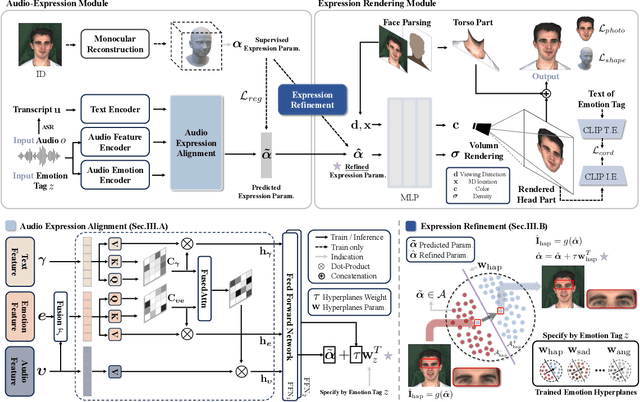
Generating emotion-specific talking head videos from audio input is an important and complex challenge for human-machine interaction. However, emotion is highly abstract concept with ambiguous boundaries, and it necessitates disentangled expression parameters to generate emotionally expressive talking head videos. In this work, we present EmoHead to synthesize talking head videos via semantic expression parameters. To predict expression parameter for arbitrary audio input, we apply an audio-expression module that can be specified by an emotion tag. This module aims to enhance correlation from audio input across various emotions. Furthermore, we leverage pre-trained hyperplane to refine facial movements by probing along the vertical direction. Finally, the refined expression parameters regularize neural radiance fields and facilitate the emotion-consistent generation of talking head videos. Experimental results demonstrate that semantic expression parameters lead to better reconstruction quality and controllability.