 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS2V-L: Vehicle-Mounted LiDAR Data Generation from Roadside Sensor Observations
Paper and Code
Mar 10, 2025

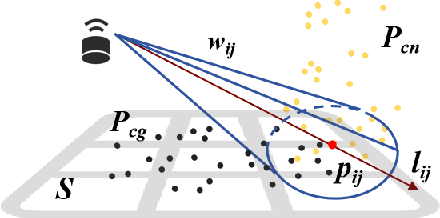

End-to-end autonomous driving solutions, which process multi-modal sensory data to directly generate refined control commands, have become a dominant paradigm in autonomous driving research. However, these approaches predominantly depend on single-vehicle data collection for model training and optimization, resulting in significant challenges such as high data acquisition and annotation costs, the scarcity of critical driving scenarios, and fragmented datasets that impede model generalization. To mitigate these limitations, we introduce RS2V-L, a novel framework for reconstructing and synthesizing vehicle-mounted LiDAR data from roadside sensor observations. Specifically, our method transforms roadside LiDAR point clouds into the vehicle-mounted LiDAR coordinate system by leveraging the target vehicle's relative pose. Subsequently, high-fidelity vehicle-mounted LiDAR data is synthesized through virtual LiDAR modeling, point cloud classification, and resampling techniques. To the best of our knowledge, this is the first approach to reconstruct vehicle-mounted LiDAR data from roadside sensor inputs. Extensive experimental evaluations demonstrate that incorporating the generated data into model training-complementing the KITTI dataset-enhances 3D object detection accuracy by over \text{30\%} while improving the efficiency of end-to-end autonomous driving data generation by more than an order of magnitude. These findings strongly validate the effectiveness of the proposed method and underscore its potential in reducing dependence on costly vehicle-mounted data collection while improving the robustness of autonomous driving models.