 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMillions of Co-purchases and Reviews Reveal the Spread of Polarization and Lifestyle Politics across Online Markets
Jan 17, 2022Polarization in America has reached a high point as markets are also becoming polarized. Existing research, however, focuses on specific market segments and products and has not evaluated this trend's full breadth. If such fault lines do spread into other segments that are not explicitly political, it would indicate the presence of lifestyle politics -- when ideas and behaviors not inherently political become politically aligned through their connections with explicitly political things. We study the pervasiveness of polarization and lifestyle politics over different product segments in a diverse market and test the extent to which consumer- and platform-level network effects and morality may explain lifestyle politics. Specifically, using graph and language data from Amazon (82.5M reviews of 9.5M products and product and category metadata from 1996-2014), we sample 234.6 million relations among 21.8 million market entities to find product categories that are most politically relevant, aligned, and polarized. We then extract moral values present in reviews' text and use these data and other reviewer-, product-, and category-level data to test whether individual- and platform- level network factors explain lifestyle politics better than products' implicit morality. We find pervasive lifestyle politics. Cultural products are 4 times more polarized than any other segment, products' political attributes have up to 3.7 times larger associations with lifestyle politics than author-level covariates, and morality has statistically significant but relatively small correlations with lifestyle politics. Examining lifestyle politics in these contexts helps us better understand the extent and root of partisan differences, why Americans may be so polarized, and how this polarization affects market systems.
Demographic Confounding Causes Extreme Instances of Lifestyle Politics on Facebook
Jan 17, 2022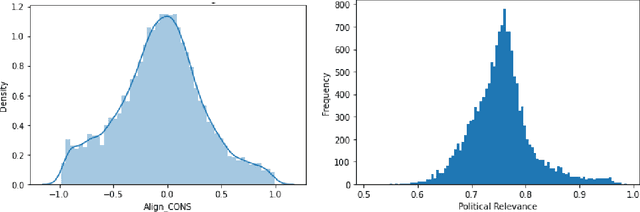

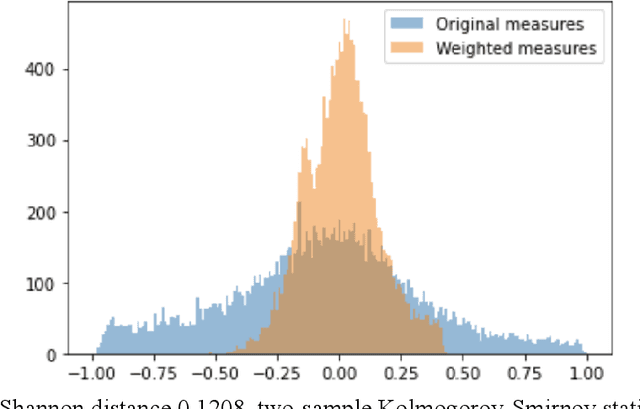

Lifestyle politics emerge when activities that have no substantive relevance to ideology become politically aligned and polarized. Homophily and social influence are able generate these fault lines on their own; however, social identities from demographics may serve as coordinating mechanisms through which lifestyle politics are mobilized are spread. Using a dataset of 137,661,886 observations from 299,327 Facebook interests aggregated across users of different racial/ethnic, education, age, gender, and income demographics, we find that the most extreme instances of lifestyle politics are those which are highly confounded by demographics such as race/ethnicity (e.g., Black artists and performers). After adjusting political alignment for demographic effects, lifestyle politics decreased by 27.36% toward the political "center" and demographically confounded interests were no longer among the most polarized interests. Instead, after demographic deconfounding, we found that the most liberal interests included electric cars, Planned Parenthood, and liberal satire while the most conservative interests included the Republican Party and conservative commentators. We validate our measures of political alignment and lifestyle politics using the General Social Survey and find similar demographic entanglements with lifestyle politics existed before social media such as Facebook were ubiquitous, giving us strong confidence that our results are not due to echo chambers or filter bubbles. Likewise, since demographic characteristics exist prior to ideological values, we argue that the demographic confounding we observe is causally responsible for the extreme instances of lifestyle politics that we find among the aggregated interests. We conclude our paper by relating our results to Simpson's paradox, cultural omnivorousness, and network autocorrelation.
Can x2vec Save Lives? Integrating Graph and Language Embeddings for Automatic Mental Health Classification
Jan 04, 2020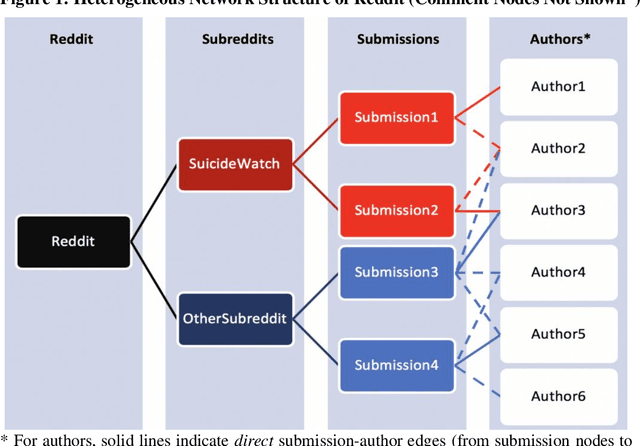
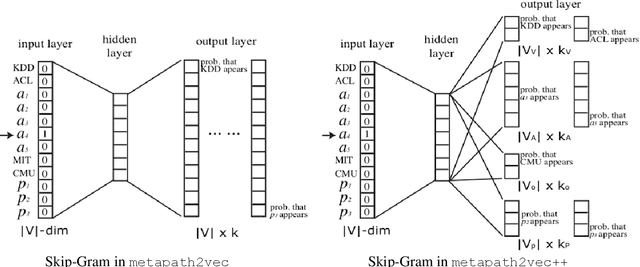
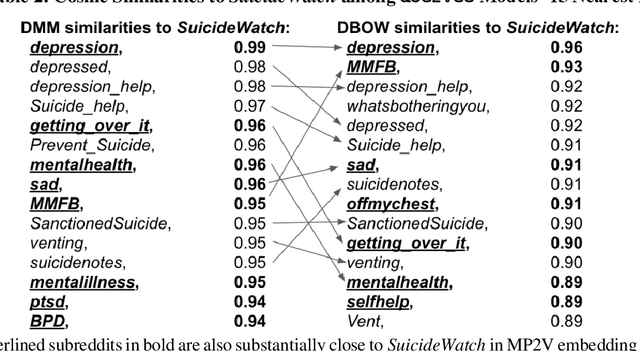
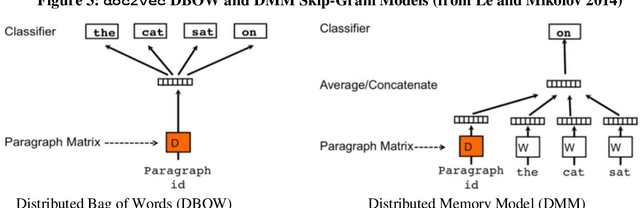
Graph and language embedding models are becoming commonplace in large scale analyses given their ability to represent complex sparse data densely in low-dimensional space. Integrating these models' complementary relational and communicative data may be especially helpful if predicting rare events or classifying members of hidden populations - tasks requiring huge and sparse datasets for generalizable analyses. For example, due to social stigma and comorbidities, mental health support groups often form in amorphous online groups. Predicting suicidality among individuals in these settings using standard network analyses is prohibitive due to resource limits (e.g., memory), and adding auxiliary data like text to such models exacerbates complexity- and sparsity-related issues. Here, I show how merging graph and language embedding models (metapath2vec and doc2vec) avoids these limits and extracts unsupervised clustering data without domain expertise or feature engineering. Graph and language distances to a suicide support group have little correlation (\r{ho} < 0.23), implying the two models are not embedding redundant information. When used separately to predict suicidality among individuals, graph and language data generate relatively accurate results (69% and 76%, respectively); however, when integrated, both data produce highly accurate predictions (90%, with 10% false-positives and 12% false-negatives). Visualizing graph embeddings annotated with predictions of potentially suicidal individuals shows the integrated model could classify such individuals even if they are positioned far from the support group. These results extend research on the importance of simultaneously analyzing behavior and language in massive networks and efforts to integrate embedding models for different kinds of data when predicting and classifying, particularly when they involve rare events.