 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan x2vec Save Lives? Integrating Graph and Language Embeddings for Automatic Mental Health Classification
Paper and Code
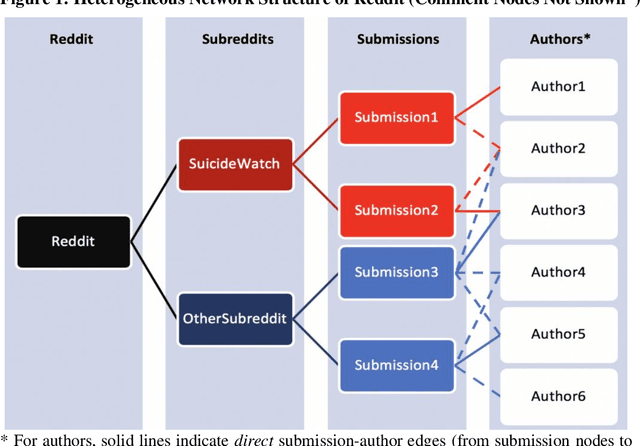
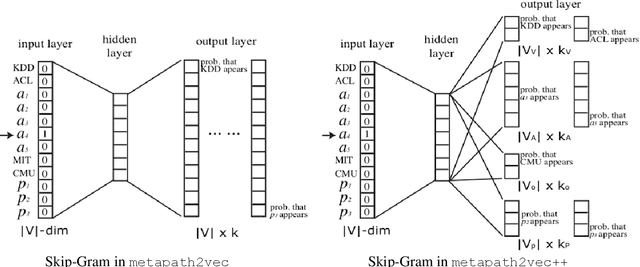
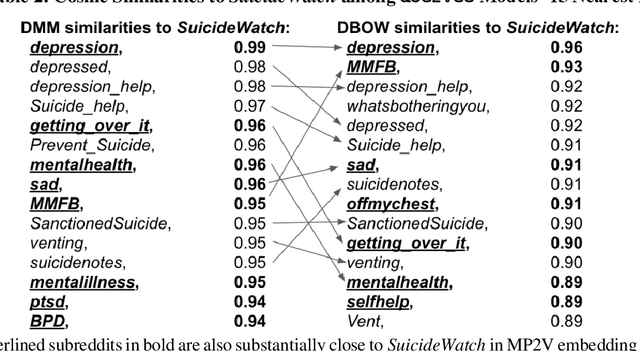
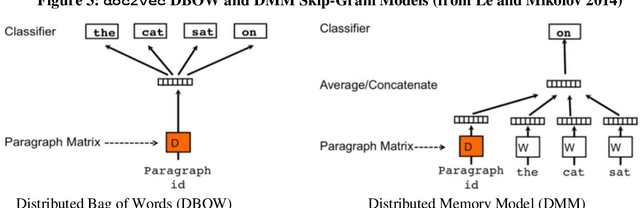
Graph and language embedding models are becoming commonplace in large scale analyses given their ability to represent complex sparse data densely in low-dimensional space. Integrating these models' complementary relational and communicative data may be especially helpful if predicting rare events or classifying members of hidden populations - tasks requiring huge and sparse datasets for generalizable analyses. For example, due to social stigma and comorbidities, mental health support groups often form in amorphous online groups. Predicting suicidality among individuals in these settings using standard network analyses is prohibitive due to resource limits (e.g., memory), and adding auxiliary data like text to such models exacerbates complexity- and sparsity-related issues. Here, I show how merging graph and language embedding models (metapath2vec and doc2vec) avoids these limits and extracts unsupervised clustering data without domain expertise or feature engineering. Graph and language distances to a suicide support group have little correlation (\r{ho} < 0.23), implying the two models are not embedding redundant information. When used separately to predict suicidality among individuals, graph and language data generate relatively accurate results (69% and 76%, respectively); however, when integrated, both data produce highly accurate predictions (90%, with 10% false-positives and 12% false-negatives). Visualizing graph embeddings annotated with predictions of potentially suicidal individuals shows the integrated model could classify such individuals even if they are positioned far from the support group. These results extend research on the importance of simultaneously analyzing behavior and language in massive networks and efforts to integrate embedding models for different kinds of data when predicting and classifying, particularly when they involve rare events.