 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Based Building Boundary Reconstruction using Attraction Field Maps
Jul 22, 2025In recent years, the number of remote satellites orbiting the Earth has grown significantly, streaming vast amounts of high-resolution visual data to support diverse applications across civil, public, and military domains. Among these applications, the generation and updating of spatial maps of the built environment have become critical due to the extensive coverage and detailed imagery provided by satellites. However, reconstructing spatial maps from satellite imagery is a complex computer vision task, requiring the creation of high-level object representations, such as primitives, to accurately capture the built environment. While the past decade has witnessed remarkable advancements in object detection and representation using visual data, primitives-based object representation remains a persistent challenge in computer vision. Consequently, high-quality spatial maps often rely on labor-intensive and manual processes. This paper introduces a novel deep learning methodology leveraging Graph Convolutional Networks (GCNs) to address these challenges in building footprint reconstruction. The proposed approach enhances performance by incorporating geometric regularity into building boundaries, integrating multi-scale and multi-resolution features, and embedding Attraction Field Maps into the network. These innovations provide a scalable and precise solution for automated building footprint extraction from a single satellite image, paving the way for impactful applications in urban planning, disaster management, and large-scale spatial analysis. Our model, Decoupled-PolyGCN, outperforms existing methods by 6% in AP and 10% in AR, demonstrating its ability to deliver accurate and regularized building footprints across diverse and challenging scenarios.
Enhancing Polygonal Building Segmentation via Oriented Corners
Jul 17, 2024The growing demand for high-resolution maps across various applications has underscored the necessity of accurately segmenting building vectors from overhead imagery. However, current deep neural networks often produce raster data outputs, leading to the need for extensive post-processing that compromises the fidelity, regularity, and simplicity of building representations. In response, this paper introduces a novel deep convolutional neural network named OriCornerNet, which directly extracts delineated building polygons from input images. Specifically, our approach involves a deep model that predicts building footprint masks, corners, and orientation vectors that indicate directions toward adjacent corners. These predictions are then used to reconstruct an initial polygon, followed by iterative refinement using a graph convolutional network that leverages semantic and geometric features. Our method inherently generates simplified polygons by initializing the refinement process with predicted corners. Also, including geometric information from oriented corners contributes to producing more regular and accurate results. Performance evaluations conducted on SpaceNet Vegas and CrowdAI-small datasets demonstrate the competitive efficacy of our approach compared to the state-of-the-art in building segmentation from overhead imagery.
HDPV-SLAM: Hybrid Depth-augmented Panoramic Visual SLAM for Mobile Mapping System with Tilted LiDAR and Panoramic Visual Camera
Jan 27, 2023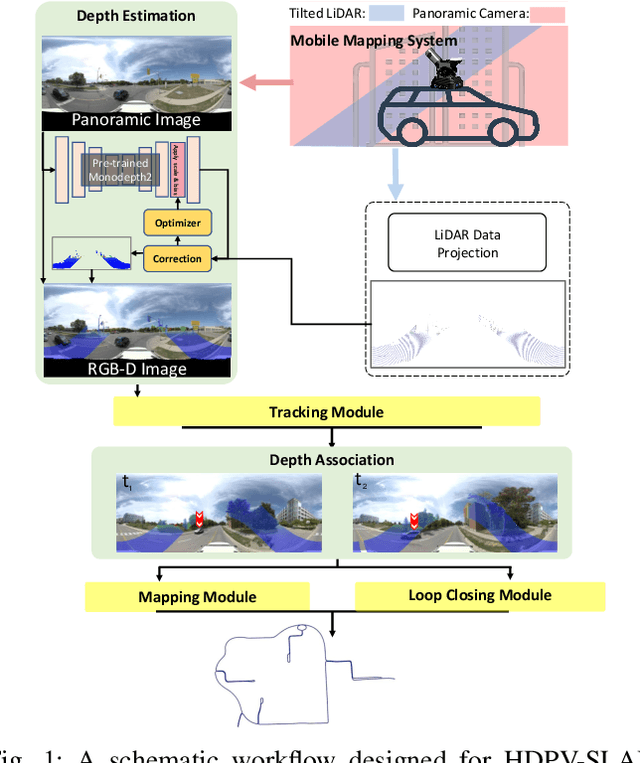
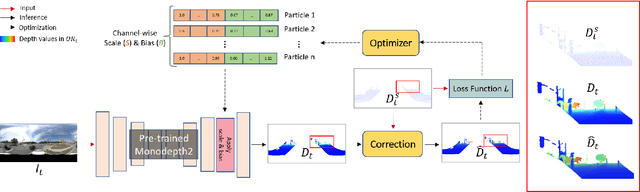


This paper proposes a novel visual simultaneous localization and mapping (SLAM), called Hybrid Depth-augmented Panoramic Visual SLAM (HDPV-SLAM), generating accurate and metrically scaled vehicle trajectories using a panoramic camera and a titled multi-beam LiDAR scanner. RGB-D SLAM served as the design foundation for HDPV-SLAM, adding depth information to visual features. It seeks to overcome the two problems that limit the performance of RGB-D SLAM systems. The first barrier is the sparseness of LiDAR depth, which makes it challenging to connect it with visual features extracted from the RGB image. We address this issue by proposing a depth estimation module for iteratively densifying sparse LiDAR depth based on deep learning (DL). The second issue relates to the challenges in the depth association caused by a significant deficiency of horizontal overlapping coverage between the panoramic camera and the tilted LiDAR sensor. To overcome this difficulty, we present a hybrid depth association module that optimally combines depth information estimated by two independent procedures, feature triangulation and depth estimation. This hybrid depth association module intends to maximize the use of more accurate depth information between the triangulated depth with visual features tracked and the DL-based corrected depth during a phase of feature tracking. We assessed HDPV-SLAM's performance using the 18.95 km-long York University and Teledyne Optech (YUTO) MMS dataset. Experimental results demonstrate that the proposed two modules significantly contribute to HDPV-SLAM's performance, which outperforms the state-of-the-art (SOTA) SLAM systems.