 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Based Building Boundary Reconstruction using Attraction Field Maps
Jul 22, 2025In recent years, the number of remote satellites orbiting the Earth has grown significantly, streaming vast amounts of high-resolution visual data to support diverse applications across civil, public, and military domains. Among these applications, the generation and updating of spatial maps of the built environment have become critical due to the extensive coverage and detailed imagery provided by satellites. However, reconstructing spatial maps from satellite imagery is a complex computer vision task, requiring the creation of high-level object representations, such as primitives, to accurately capture the built environment. While the past decade has witnessed remarkable advancements in object detection and representation using visual data, primitives-based object representation remains a persistent challenge in computer vision. Consequently, high-quality spatial maps often rely on labor-intensive and manual processes. This paper introduces a novel deep learning methodology leveraging Graph Convolutional Networks (GCNs) to address these challenges in building footprint reconstruction. The proposed approach enhances performance by incorporating geometric regularity into building boundaries, integrating multi-scale and multi-resolution features, and embedding Attraction Field Maps into the network. These innovations provide a scalable and precise solution for automated building footprint extraction from a single satellite image, paving the way for impactful applications in urban planning, disaster management, and large-scale spatial analysis. Our model, Decoupled-PolyGCN, outperforms existing methods by 6% in AP and 10% in AR, demonstrating its ability to deliver accurate and regularized building footprints across diverse and challenging scenarios.
Enhancing Polygonal Building Segmentation via Oriented Corners
Jul 17, 2024The growing demand for high-resolution maps across various applications has underscored the necessity of accurately segmenting building vectors from overhead imagery. However, current deep neural networks often produce raster data outputs, leading to the need for extensive post-processing that compromises the fidelity, regularity, and simplicity of building representations. In response, this paper introduces a novel deep convolutional neural network named OriCornerNet, which directly extracts delineated building polygons from input images. Specifically, our approach involves a deep model that predicts building footprint masks, corners, and orientation vectors that indicate directions toward adjacent corners. These predictions are then used to reconstruct an initial polygon, followed by iterative refinement using a graph convolutional network that leverages semantic and geometric features. Our method inherently generates simplified polygons by initializing the refinement process with predicted corners. Also, including geometric information from oriented corners contributes to producing more regular and accurate results. Performance evaluations conducted on SpaceNet Vegas and CrowdAI-small datasets demonstrate the competitive efficacy of our approach compared to the state-of-the-art in building segmentation from overhead imagery.
Spatial Layout Consistency for 3D Semantic Segmentation
Mar 02, 2023Due to the aged nature of much of the utility network infrastructure, developing a robust and trustworthy computer vision system capable of inspecting it with minimal human intervention has attracted considerable research attention. The airborne laser terrain mapping (ALTM) system quickly becomes the central data collection system among the numerous available sensors. Its ability to penetrate foliage with high-powered energy provides wide coverage and achieves survey-grade ranging accuracy. However, the post-data acquisition process for classifying the ALTM's dense and irregular point clouds is a critical bottleneck that must be addressed to improve efficiency and accuracy. We introduce a novel deep convolutional neural network (DCNN) technique for achieving voxel-based semantic segmentation of the ALTM's point clouds. The suggested deep learning method, Semantic Utility Network (SUNet) is a multi-dimensional and multi-resolution network. SUNet combines two networks: one classifies point clouds at multi-resolution with object categories in three dimensions and another predicts two-dimensional regional labels distinguishing corridor regions from non-corridors. A significant innovation of the SUNet is that it imposes spatial layout consistency on the outcomes of voxel-based and regional segmentation results. The proposed multi-dimensional DCNN combines hierarchical context for spatial layout embedding with a coarse-to-fine strategy. We conducted a comprehensive ablation study to test SUNet's performance using 67 km x 67 km of utility corridor data at a density of 5pp/m2. Our experiments demonstrated that SUNet's spatial layout consistency and a multi-resolution feature aggregation could significantly improve performance, outperforming the SOTA baseline network and achieving a good F1 score for pylon 89%, ground 99%, vegetation 99% and powerline 98% classes.
NSANet: Noise Seeking Attention Network
Feb 26, 2023LiDAR (Light Detection and Ranging) technology has remained popular in capturing natural and built environments for numerous applications. The recent technological advancements in electro-optical engineering have aided in obtaining laser returns at a higher pulse repetition frequency (PRF), which considerably increased the density of the 3D point cloud. Conventional techniques with lower PRF had a single pulse-in-air (SPIA) zone, large enough to avoid a mismatch among pulse pairs at the receiver. New multiple pulses-in-air (MPIA) technology guarantees various windows of operational ranges for a single flight line and no blind zones. The disadvantage of the technology is the projection of atmospheric returns closer to the same pulse-in-air zone of adjacent terrain points likely to intersect with objects of interest. These noise properties compromise the perceived quality of the scene and encourage the development of new noise-filtering neural networks, as existing filters are significantly ineffective. We propose a novel dual-attention noise-filtering neural network called Noise Seeking Attention Network (NSANet) that uses physical priors and local spatial attention to filter noise. Our research is motivated by two psychology theories of feature integration and attention engagement to prove the role of attention in computer vision at the encoding and decoding phase. The presented results of NSANet show the inclination towards attention engagement theory and a performance boost compared to the state-of-the-art noise-filtering deep convolutional neural networks.
Deep Convolutional Neural Network for Plume Rise Measurements in Industrial Environments
Feb 15, 2023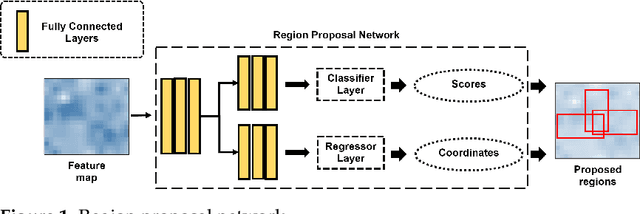
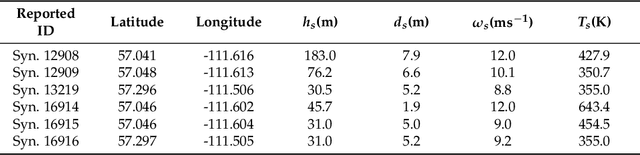
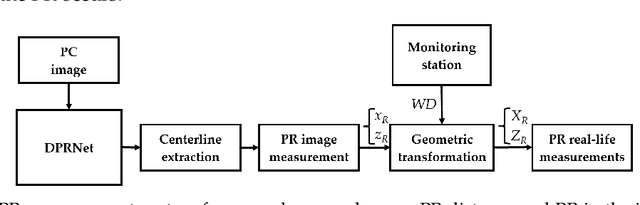
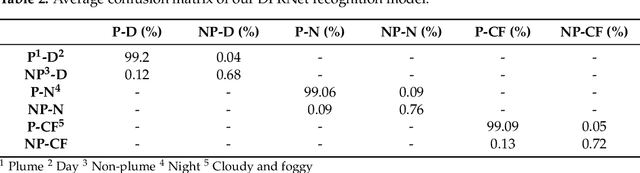
The estimation of plume cloud height is essential for air-quality transport models, local environmental assessment cases, and global climate models. When pollutants are released by a smokestack, plume rise is the constant height at which the plume cloud is carried downwind as its momentum dissipates and the temperatures of the plume cloud and the ambient equalize. Although different parameterizations and equations are used in most air quality models to predict plume rise, verification of these parameterizations has been limited in the past three decades. Beyond validation, there is also value in real-time measurement of plume rise to improve the accuracy of air quality forecasting. In this paper, we propose a low-cost measurement technology that can monitor smokestack plumes and make long-term, real-time measurements of plume rise, improving predictability. To do this, a two-stage method is developed based on deep convolutional neural networks. In the first stage, an improved Mask R-CNN is applied to detect the plume cloud borders and distinguish the plume from its background and other objects. This proposed model is called Deep Plume Rise Net (DPRNet). In the second stage, a geometric transformation phase is applied through the wind direction information from a nearby monitoring station to obtain real-life measurements of different parameters. Finally, the plume cloud boundaries are obtained to calculate the plume rise. Various images with different atmospheric conditions, including day, night, cloudy, and foggy, have been selected for DPRNet training algorithm. Obtained results show the proposed method outperforms widely-used networks in plume cloud border detection and recognition.
TPE-Net: Track Point Extraction and Association Network for Rail Path Proposal Generation
Feb 11, 2023One essential feature of an autonomous train is minimizing collision risks with third-party objects. To estimate the risk, the control system must identify topological information of all the rail routes ahead on which the train can possibly move, especially within merging or diverging rails. This way, the train can figure out the status of potential obstacles with respect to its route and hence, make a timely decision. Numerous studies have successfully extracted all rail tracks as a whole within forward-looking images without considering element instances. Still, some image-based methods have employed hard-coded prior knowledge of railway geometry on 3D data to associate left-right rails and generate rail route instances. However, we propose a rail path extraction pipeline in which left-right rail pixels of each rail route instance are extracted and associated through a fully convolutional encoder-decoder architecture called TPE-Net. Two different regression branches for TPE-Net are proposed to regress the locations of center points of each rail route, along with their corresponding left-right pixels. Extracted rail pixels are then spatially clustered to generate topological information of all the possible train routes (ego-paths), discarding non-ego-path ones. Experimental results on a challenging, publicly released benchmark show true-positive-pixel level average precision and recall of 0.9207 and 0.8721, respectively, at about 12 frames per second. Even though our evaluation results are not higher than the SOTA, the proposed regression pipeline performs remarkably in extracting the correspondences by looking once at the image. It generates strong rail route hypotheses without reliance on camera parameters, 3D data, and geometrical constraints.
MRNet: Multiple-Input Receptive Field Network for Large-Scale Point Cloud Segmentation
Jan 30, 2023



The size of the input receptive field is one of the most critical aspects in the semantic segmentation of the point cloud, yet it is one of the most overlooked parameters. This paper presents the multiple-input receptive field processing semantic segmentation network MRNet. The fundamental philosophy of our design is to overcome the size of the input receptive field dilemma. In particular, the input receptive field's size significantly impacts the performance of different sizes of objects. To overcome this, we introduce a parallel processing network with connection modules between the parallel streams. Our ablation studies show the effectiveness of implemented modules. Also, we set the new state-of-art performance on the large-scale point cloud dataset SensatUrban.
HDPV-SLAM: Hybrid Depth-augmented Panoramic Visual SLAM for Mobile Mapping System with Tilted LiDAR and Panoramic Visual Camera
Jan 27, 2023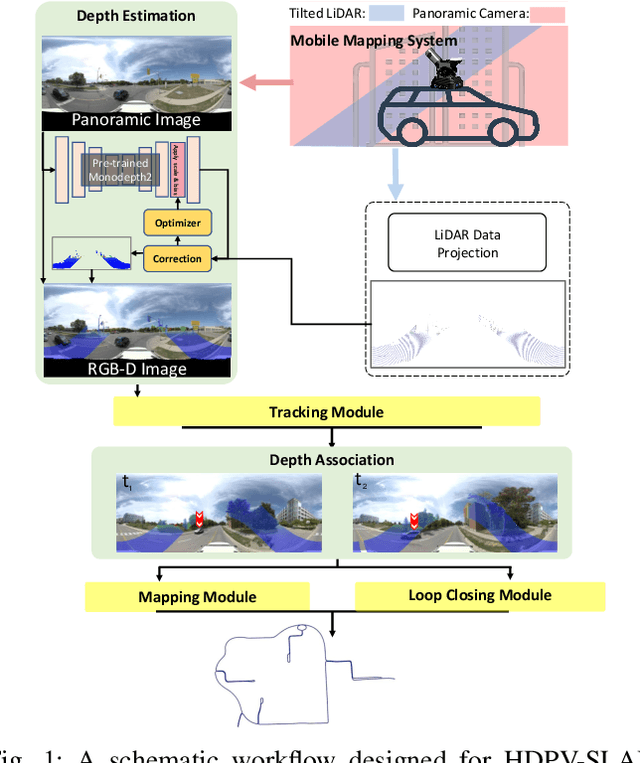
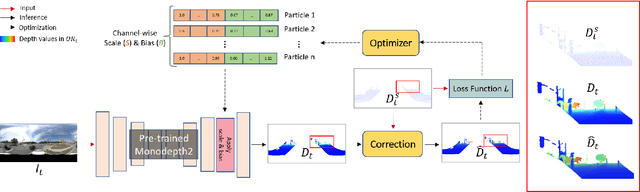


This paper proposes a novel visual simultaneous localization and mapping (SLAM), called Hybrid Depth-augmented Panoramic Visual SLAM (HDPV-SLAM), generating accurate and metrically scaled vehicle trajectories using a panoramic camera and a titled multi-beam LiDAR scanner. RGB-D SLAM served as the design foundation for HDPV-SLAM, adding depth information to visual features. It seeks to overcome the two problems that limit the performance of RGB-D SLAM systems. The first barrier is the sparseness of LiDAR depth, which makes it challenging to connect it with visual features extracted from the RGB image. We address this issue by proposing a depth estimation module for iteratively densifying sparse LiDAR depth based on deep learning (DL). The second issue relates to the challenges in the depth association caused by a significant deficiency of horizontal overlapping coverage between the panoramic camera and the tilted LiDAR sensor. To overcome this difficulty, we present a hybrid depth association module that optimally combines depth information estimated by two independent procedures, feature triangulation and depth estimation. This hybrid depth association module intends to maximize the use of more accurate depth information between the triangulated depth with visual features tracked and the DL-based corrected depth during a phase of feature tracking. We assessed HDPV-SLAM's performance using the 18.95 km-long York University and Teledyne Optech (YUTO) MMS dataset. Experimental results demonstrate that the proposed two modules significantly contribute to HDPV-SLAM's performance, which outperforms the state-of-the-art (SOTA) SLAM systems.
Boundary Regularized Building Footprint Extraction From Satellite Images Using Deep Neural Network
Jun 23, 2020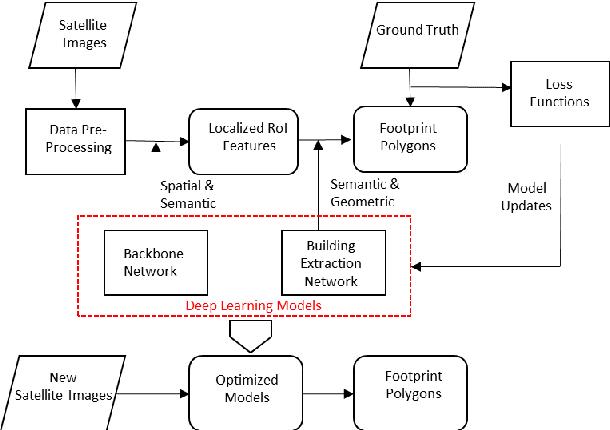
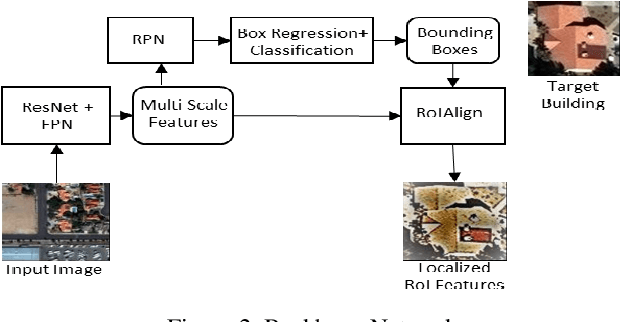
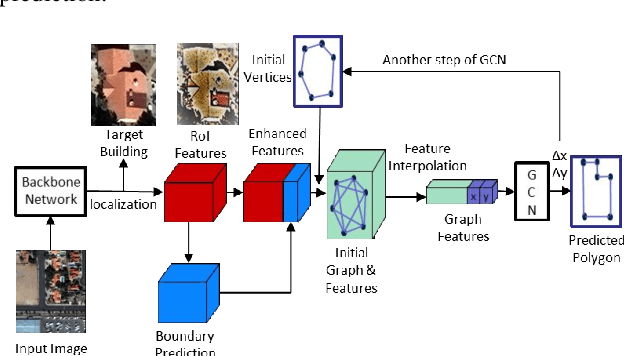
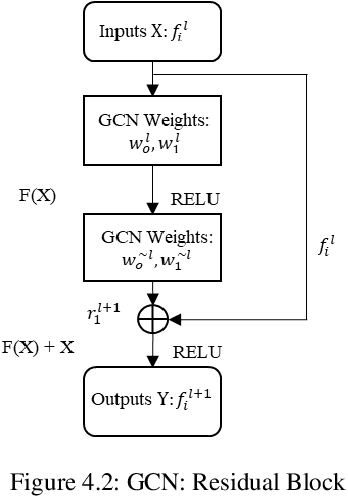
In recent years, an ever-increasing number of remote satellites are orbiting the Earth which streams vast amount of visual data to support a wide range of civil, public and military applications. One of the key information obtained from satellite imagery is to produce and update spatial maps of built environment due to its wide coverage with high resolution data. However, reconstructing spatial maps from satellite imagery is not a trivial vision task as it requires reconstructing a scene or object with high-level representation such as primitives. For the last decade, significant advancement in object detection and representation using visual data has been achieved, but the primitive-based object representation still remains as a challenging vision task. Thus, a high-quality spatial map is mainly produced through complex labour-intensive processes. In this paper, we propose a novel deep neural network, which enables to jointly detect building instance and regularize noisy building boundary shapes from a single satellite imagery. The proposed deep learning method consists of a two-stage object detection network to produce region of interest (RoI) features and a building boundary extraction network using graph models to learn geometric information of the polygon shapes. Extensive experiments show that our model can accomplish multi-tasks of object localization, recognition, semantic labelling and geometric shape extraction simultaneously. In terms of building extraction accuracy, computation efficiency and boundary regularization performance, our model outperforms the state-of-the-art baseline models.