 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVCNet: Scribble-based Video Colorization Network with Temporal Aggregation
Mar 21, 2023In this paper, we propose a scribble-based video colorization network with temporal aggregation called SVCNet. It can colorize monochrome videos based on different user-given color scribbles. It addresses three common issues in the scribble-based video colorization area: colorization vividness, temporal consistency, and color bleeding. To improve the colorization quality and strengthen the temporal consistency, we adopt two sequential sub-networks in SVCNet for precise colorization and temporal smoothing, respectively. The first stage includes a pyramid feature encoder to incorporate color scribbles with a grayscale frame, and a semantic feature encoder to extract semantics. The second stage finetunes the output from the first stage by aggregating the information of neighboring colorized frames (as short-range connections) and the first colorized frame (as a long-range connection). To alleviate the color bleeding artifacts, we learn video colorization and segmentation simultaneously. Furthermore, we set the majority of operations on a fixed small image resolution and use a Super-resolution Module at the tail of SVCNet to recover original sizes. It allows the SVCNet to fit different image resolutions at the inference. Finally, we evaluate the proposed SVCNet on DAVIS and Videvo benchmarks. The experimental results demonstrate that SVCNet produces both higher-quality and more temporally consistent videos than other well-known video colorization approaches. The codes and models can be found at https://github.com/zhaoyuzhi/SVCNet.
CSRNet: Cascaded Selective Resolution Network for Real-time Semantic Segmentation
Jun 08, 2021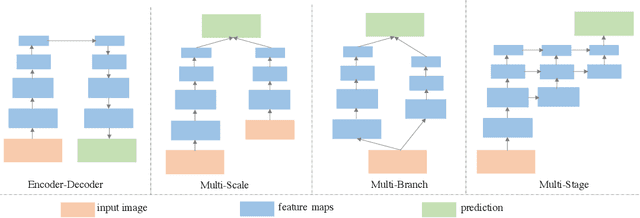
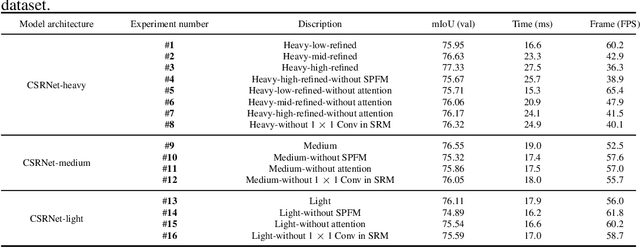
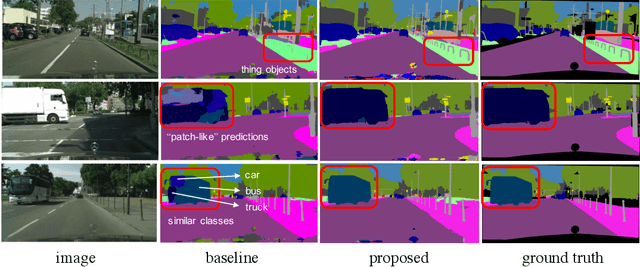
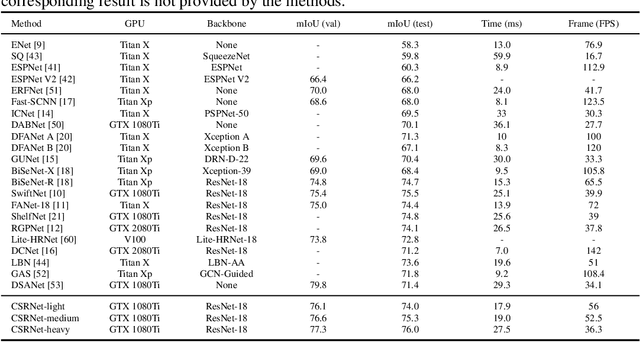
Real-time semantic segmentation has received considerable attention due to growing demands in many practical applications, such as autonomous vehicles, robotics, etc. Existing real-time segmentation approaches often utilize feature fusion to improve segmentation accuracy. However, they fail to fully consider the feature information at different resolutions and the receptive fields of the networks are relatively limited, thereby compromising the performance. To tackle this problem, we propose a light Cascaded Selective Resolution Network (CSRNet) to improve the performance of real-time segmentation through multiple context information embedding and enhanced feature aggregation. The proposed network builds a three-stage segmentation system, which integrates feature information from low resolution to high resolution and achieves feature refinement progressively. CSRNet contains two critical modules: the Shorted Pyramid Fusion Module (SPFM) and the Selective Resolution Module (SRM). The SPFM is a computationally efficient module to incorporate the global context information and significantly enlarge the receptive field at each stage. The SRM is designed to fuse multi-resolution feature maps with various receptive fields, which assigns soft channel attentions across the feature maps and helps to remedy the problem caused by multi-scale objects. Comprehensive experiments on two well-known datasets demonstrate that the proposed CSRNet effectively improves the performance for real-time segmentation.