 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSRNet: Cascaded Selective Resolution Network for Real-time Semantic Segmentation
Jun 08, 2021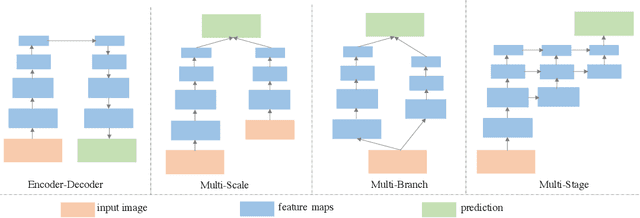
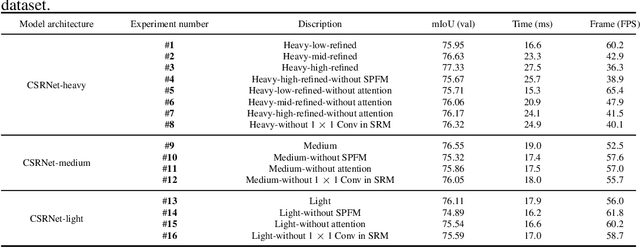
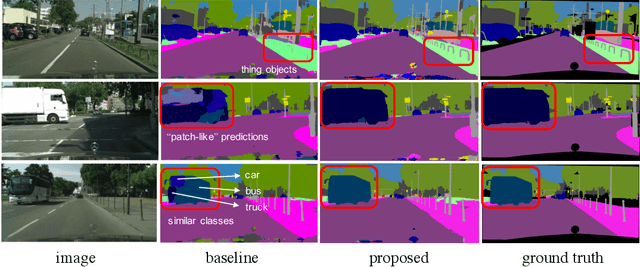
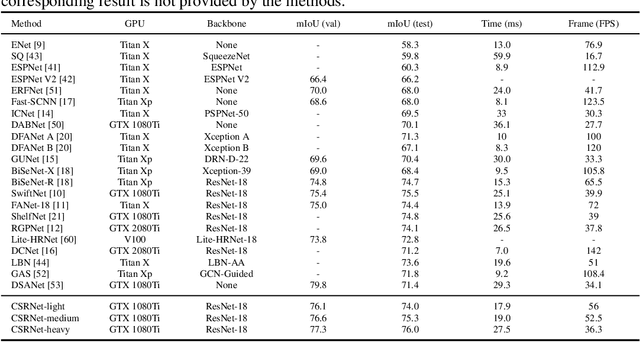
Real-time semantic segmentation has received considerable attention due to growing demands in many practical applications, such as autonomous vehicles, robotics, etc. Existing real-time segmentation approaches often utilize feature fusion to improve segmentation accuracy. However, they fail to fully consider the feature information at different resolutions and the receptive fields of the networks are relatively limited, thereby compromising the performance. To tackle this problem, we propose a light Cascaded Selective Resolution Network (CSRNet) to improve the performance of real-time segmentation through multiple context information embedding and enhanced feature aggregation. The proposed network builds a three-stage segmentation system, which integrates feature information from low resolution to high resolution and achieves feature refinement progressively. CSRNet contains two critical modules: the Shorted Pyramid Fusion Module (SPFM) and the Selective Resolution Module (SRM). The SPFM is a computationally efficient module to incorporate the global context information and significantly enlarge the receptive field at each stage. The SRM is designed to fuse multi-resolution feature maps with various receptive fields, which assigns soft channel attentions across the feature maps and helps to remedy the problem caused by multi-scale objects. Comprehensive experiments on two well-known datasets demonstrate that the proposed CSRNet effectively improves the performance for real-time segmentation.
Spatial Content Alignment For Pose Transfer
Mar 31, 2021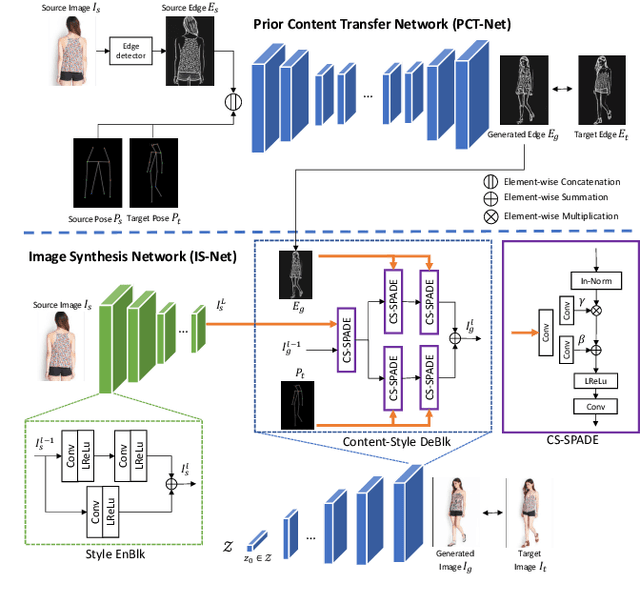
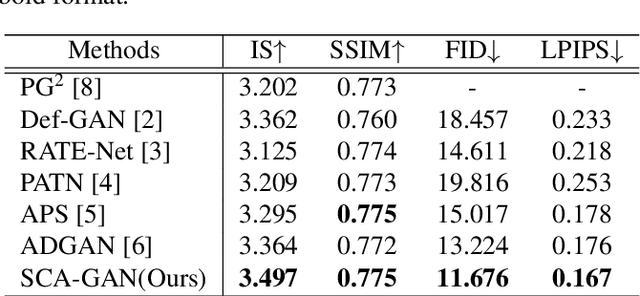


Due to unreliable geometric matching and content misalignment, most conventional pose transfer algorithms fail to generate fine-trained person images. In this paper, we propose a novel framework Spatial Content Alignment GAN (SCAGAN) which aims to enhance the content consistency of garment textures and the details of human characteristics. We first alleviate the spatial misalignment by transferring the edge content to the target pose in advance. Secondly, we introduce a new Content-Style DeBlk which can progressively synthesize photo-realistic person images based on the appearance features of the source image, the target pose heatmap and the prior transferred content in edge domain. We compare the proposed framework with several state-of-the-art methods to show its superiority in quantitative and qualitative analysis. Moreover, detailed ablation study results demonstrate the efficacy of our contributions. Codes are publicly available at github.com/rocketappslab/SCA-GAN.