 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChildPredictor: A Child Face Prediction Framework with Disentangled Learning
Paper and Code
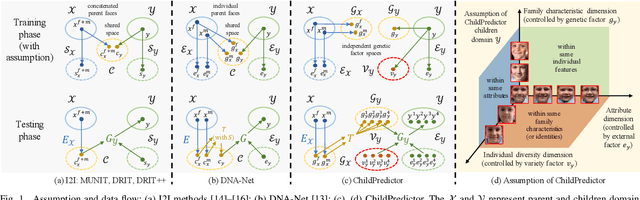

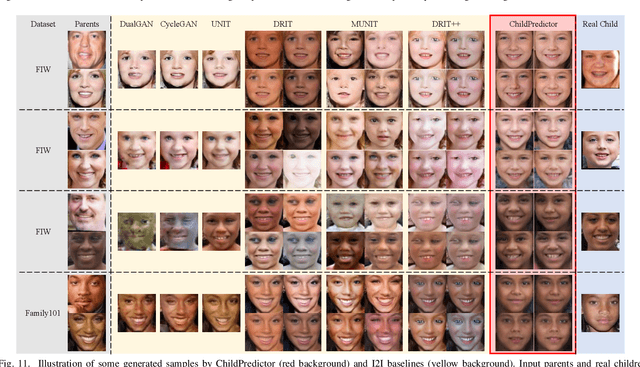

The appearances of children are inherited from their parents, which makes it feasible to predict them. Predicting realistic children's faces may help settle many social problems, such as age-invariant face recognition, kinship verification, and missing child identification. It can be regarded as an image-to-image translation task. Existing approaches usually assume domain information in the image-to-image translation can be interpreted by "style", i.e., the separation of image content and style. However, such separation is improper for the child face prediction, because the facial contours between children and parents are not the same. To address this issue, we propose a new disentangled learning strategy for children's face prediction. We assume that children's faces are determined by genetic factors (compact family features, e.g., face contour), external factors (facial attributes irrelevant to prediction, such as moustaches and glasses), and variety factors (individual properties for each child). On this basis, we formulate predictions as a mapping from parents' genetic factors to children's genetic factors, and disentangle them from external and variety factors. In order to obtain accurate genetic factors and perform the mapping, we propose a ChildPredictor framework. It transfers human faces to genetic factors by encoders and back by generators. Then, it learns the relationship between the genetic factors of parents and children through a mapping function. To ensure the generated faces are realistic, we collect a large Family Face Database to train ChildPredictor and evaluate it on the FF-Database validation set. Experimental results demonstrate that ChildPredictor is superior to other well-known image-to-image translation methods in predicting realistic and diverse child faces. Implementation codes can be found at https://github.com/zhaoyuzhi/ChildPredictor.