 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIES: Autonomous Reasoning with LLMs on Interactive Thought Graph Environments
Feb 28, 2025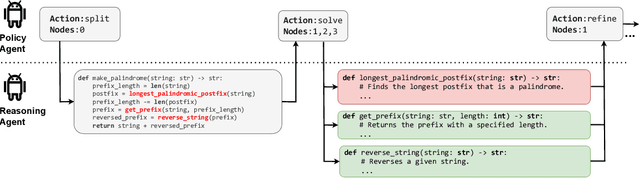



Recent research has shown that LLM performance on reasoning tasks can be enhanced by scaling test-time compute. One promising approach, particularly with decomposable problems, involves arranging intermediate solutions as a graph on which transformations are performed to explore the solution space. However, prior works rely on pre-determined, task-specific transformation schedules which are subject to a set of searched hyperparameters. In this work, we view thought graph transformations as actions in a Markov decision process, and implement policy agents to drive effective action policies for the underlying reasoning LLM agent. In particular, we investigate the ability for another LLM to act as a policy agent on thought graph environments and introduce ARIES, a multi-agent architecture for reasoning with LLMs. In ARIES, reasoning LLM agents solve decomposed subproblems, while policy LLM agents maintain visibility of the thought graph states, and dynamically adapt the problem-solving strategy. Through extensive experiments, we observe that using off-the-shelf LLMs as policy agents with no supervised fine-tuning (SFT) can yield up to $29\%$ higher accuracy on HumanEval relative to static transformation schedules, as well as reducing inference costs by $35\%$ and avoid any search requirements. We also conduct a thorough analysis of observed failure modes, highlighting that limitations on LLM sizes and the depth of problem decomposition can be seen as challenges to scaling LLM-guided reasoning.
Understanding Public Safety Trends in Calgary through data mining
Jul 30, 2024This paper utilizes statistical data from various open datasets in Calgary to to uncover patterns and insights for community crimes, disorders, and traffic incidents. Community attributes like demographics, housing, and pet registration were collected and analyzed through geospatial visualization and correlation analysis. Strongly correlated features were identified using the chi-square test, and predictive models were built using association rule mining and machine learning algorithms. The findings suggest that crime rates are closely linked to factors such as population density, while pet registration has a smaller impact. This study offers valuable insights for city managers to enhance community safety strategies.
Incrementality Bidding and Attribution
Aug 25, 2022The causal effect of showing an ad to a potential customer versus not, commonly referred to as "incrementality", is the fundamental question of advertising effectiveness. In digital advertising three major puzzle pieces are central to rigorously quantifying advertising incrementality: ad buying/bidding/pricing, attribution, and experimentation. Building on the foundations of machine learning and causal econometrics, we propose a methodology that unifies these three concepts into a computationally viable model of both bidding and attribution which spans the randomization, training, cross validation, scoring, and conversion attribution of advertising's causal effects. Implementation of this approach is likely to secure a significant improvement in the return on investment of advertising.
You Only Compress Once: Optimal Data Compression for Estimating Linear Models
Mar 03, 2021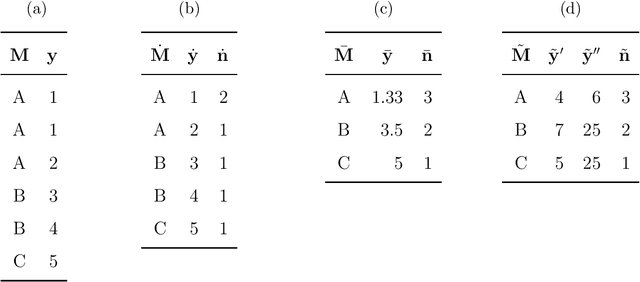


Linear models are used in online decision making, such as in machine learning, policy algorithms, and experimentation platforms. Many engineering systems that use linear models achieve computational efficiency through distributed systems and expert configuration. While there are strengths to this approach, it is still difficult to have an environment that enables researchers to interactively iterate and explore data and models, as well as leverage analytics solutions from the open source community. Consequently, innovation can be blocked. Conditionally sufficient statistics is a unified data compression and estimation strategy that is useful for the model development process, as well as the engineering deployment process. The strategy estimates linear models from compressed data without loss on the estimated parameters and their covariances, even when errors are autocorrelated within clusters of observations. Additionally, the compression preserves almost all interactions with the the original data, unlocking better productivity for both researchers and engineering systems.