 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanHAR: Dual Attention Network For Multimodal Human Activity Recognition Using Wearable Sensors
Paper and Code
Jun 25, 2020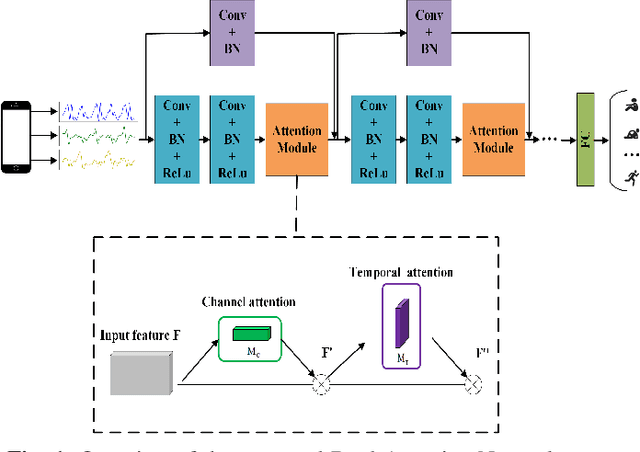
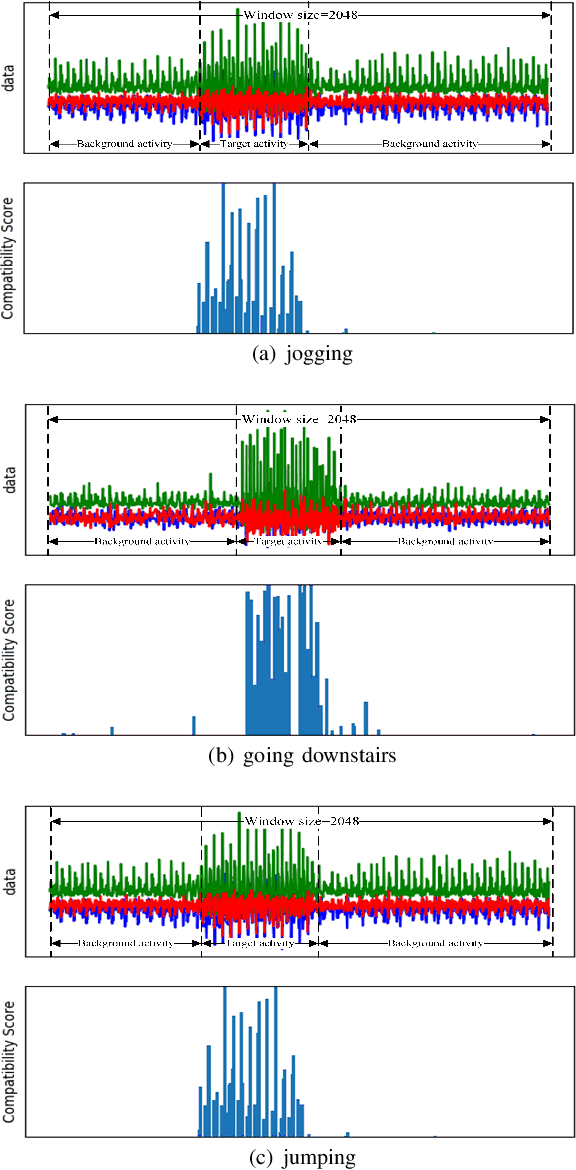
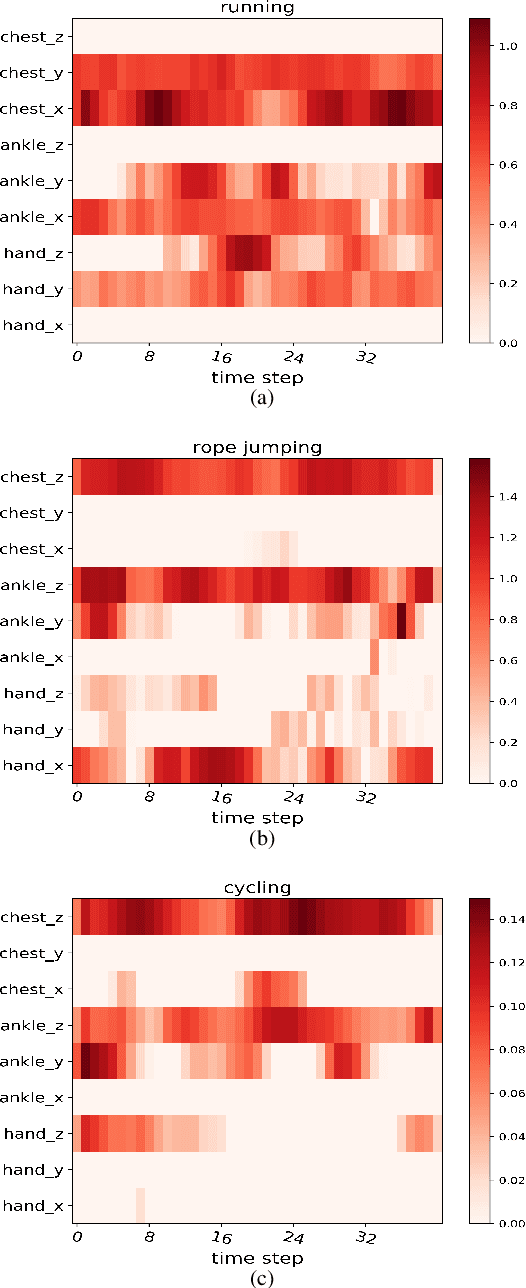
Human activity recognition (HAR) in ubiquitous computing has been beginning to incorporate attention into the context of deep neural networks (DNNs), in which the rich sensing data from multimodal sensors such as accelerometer and gyroscope is used to infer human activities. Recently, two attention methods are proposed via combining with Gated Recurrent Units (GRU) and Long Short-Term Memory (LSTM) network, which can capture the dependencies of sensing signals in both spatial and temporal domains simultaneously. However, recurrent networks often have a weak feature representing power compared with convolutional neural networks (CNNs). On the other hand, two attention, i.e., hard attention and soft attention, are applied in temporal domains via combining with CNN, which pay more attention to the target activity from a long sequence. However, they can only tell where to focus and miss channel information, which plays an important role in deciding what to focus. As a result, they fail to address the spatial-temporal dependencies of multimodal sensing signals, compared with attention-based GRU or LSTM. In the paper, we propose a novel dual attention method called DanHAR, which introduces the framework of blending channel attention and temporal attention on a CNN, demonstrating superiority in improving the comprehensibility for multimodal HAR. Extensive experiments on four public HAR datasets and weakly labeled dataset show that DanHAR achieves state-of-the-art performance with negligible overhead of parameters. Furthermore, visualizing analysis is provided to show that our attention can amplifies more important sensor modalities and timesteps during classification, which agrees well with human common intuition.