 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Unlearning is Not "on Edge"! An Adaptive Exact Unlearning System on Resource-Constrained Devices
Paper and Code
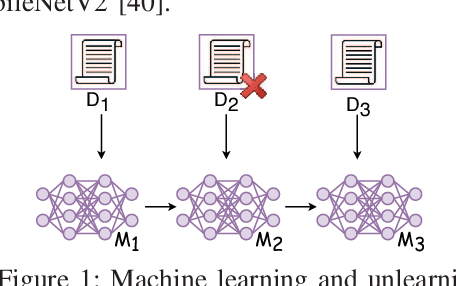
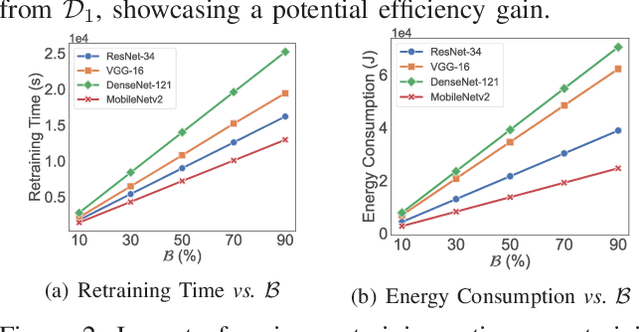
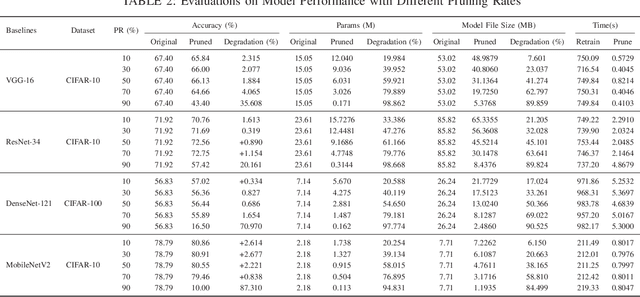
The right to be forgotten mandates that machine learning models enable the erasure of a data owner's data and information from a trained model. Removing data from the dataset alone is inadequate, as machine learning models can memorize information from the training data, increasing the potential privacy risk to users. To address this, multiple machine unlearning techniques have been developed and deployed. Among them, approximate unlearning is a popular solution, but recent studies report that its unlearning effectiveness is not fully guaranteed. Another approach, exact unlearning, tackles this issue by discarding the data and retraining the model from scratch, but at the cost of considerable computational and memory resources. However, not all devices have the capability to perform such retraining. In numerous machine learning applications, such as edge devices, Internet-of-Things (IoT), mobile devices, and satellites, resources are constrained, posing challenges for deploying existing exact unlearning methods. In this study, we propose a Constraint-aware Adaptive Exact Unlearning System at the network Edge (CAUSE), an approach to enabling exact unlearning on resource-constrained devices. Aiming to minimize the retrain overhead by storing sub-models on the resource-constrained device, CAUSE innovatively applies a Fibonacci-based replacement strategy and updates the number of shards adaptively in the user-based data partition process. To further improve the effectiveness of memory usage, CAUSE leverages the advantage of model pruning to save memory via compression with minimal accuracy sacrifice. The experimental results demonstrate that CAUSE significantly outperforms other representative systems in realizing exact unlearning on the resource-constrained device by 9.23%-80.86%, 66.21%-83.46%, and 5.26%-194.13% in terms of unlearning speed, energy consumption, and accuracy.