 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Mar 19, 2024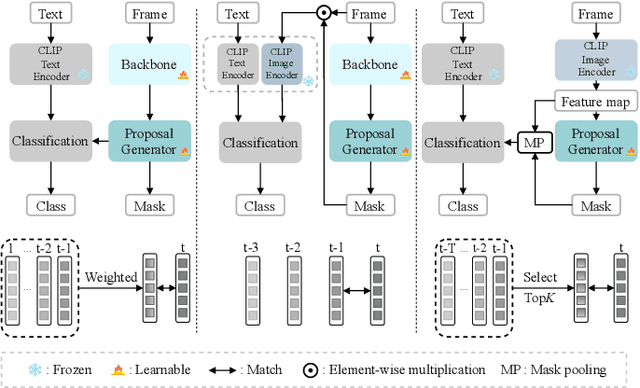
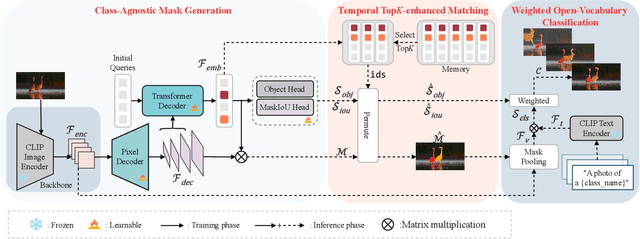
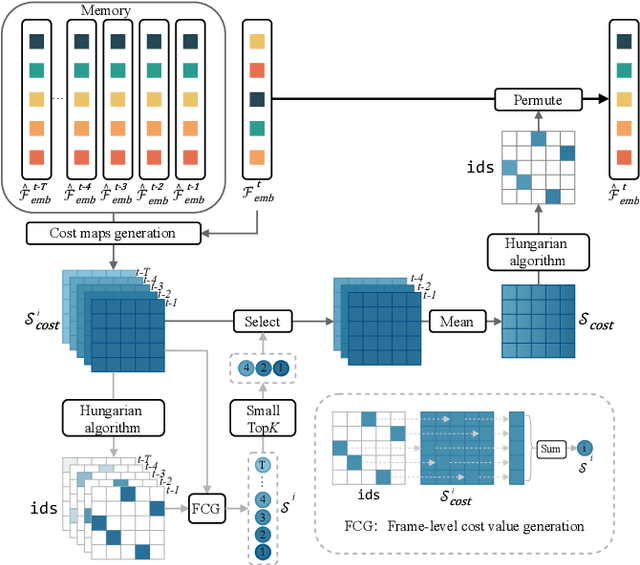

Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown strong zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores. Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.1% and 40.3% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.0% and 24.0% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.