 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFingerNet: Noise-Adaptive Speech Enhancement for Hearing Aids
Jan 17, 2025



The \textbf{DeepFilterNet} (\textbf{DFN}) architecture was recently proposed as a deep learning model suited for hearing aid devices. Despite its competitive performance on numerous benchmarks, it still follows a `one-size-fits-all' approach, which aims to train a single, monolithic architecture that generalises across different noises and environments. However, its limited size and computation budget can hamper its generalisability. Recent work has shown that in-context adaptation can improve performance by conditioning the denoising process on additional information extracted from background recordings to mitigate this. These recordings can be offloaded outside the hearing aid, thus improving performance while adding minimal computational overhead. We introduce these principles to the \textbf{DFN} model, thus proposing the \textbf{DFingerNet} (\textbf{DFiN}) model, which shows superior performance on various benchmarks inspired by the DNS Challenge.
Deep Multi-Frame Filtering for Hearing Aids
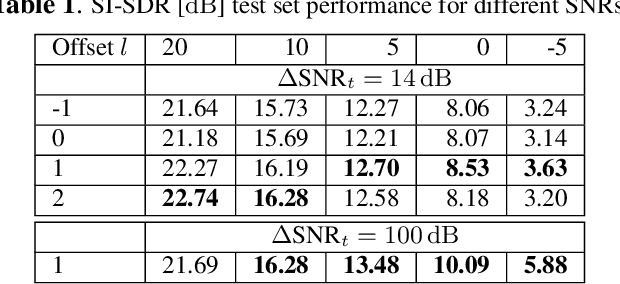
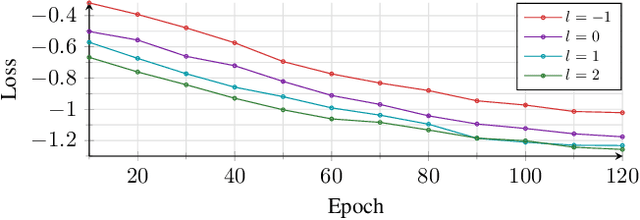
May 14, 2023Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep filtering (DF) recently demonstrated its capabilities for low-latency scenarios like hearing aids with its complex multi-frame (MF) filter. Alternatively, the complex filter can be estimated via an MF minimum variance distortionless response (MVDR), or MF Wiener filter (WF). Previous studies have shown that incorporating algorithm domain knowledge using an MVDR filter might be beneficial compared to the direct filter estimation via DF. In this work, we compare the usage of various multi-frame filters such as DF, MF-MVDR, or MF-WF for HAs. We assess different covariance estimation methods for both MF-MVDR and MF-WF and objectively demonstrate an improved performance compared to direct DF estimation, significantly outperforming related work while improving the runtime performance.
DeepFilterNet: Perceptually Motivated Real-Time Speech Enhancement
May 14, 2023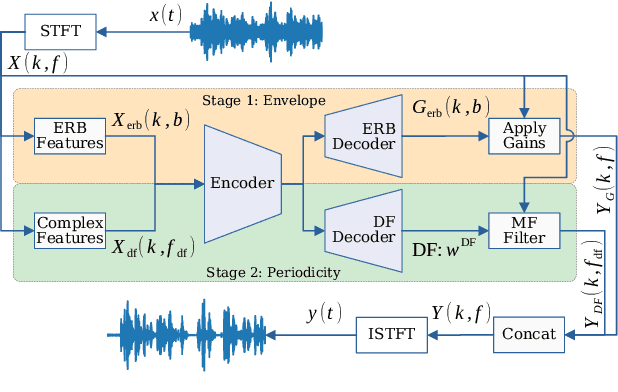


Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep Filtering (DF) was proposed to directly estimate a complex filter in frequency domain to take advantage of these correlations. In this work, we present a real-time speech enhancement demo using DeepFilterNet. DeepFilterNet's efficiency is enabled by exploiting domain knowledge of speech production and psychoacoustic perception. Our model is able to match state-of-the-art speech enhancement benchmarks while achieving a real-time-factor of 0.19 on a single threaded notebook CPU. The framework as well as pretrained weights have been published under an open source license.
DeepFilterNet2: Towards Real-Time Speech Enhancement on Embedded Devices for Full-Band Audio
May 11, 2022
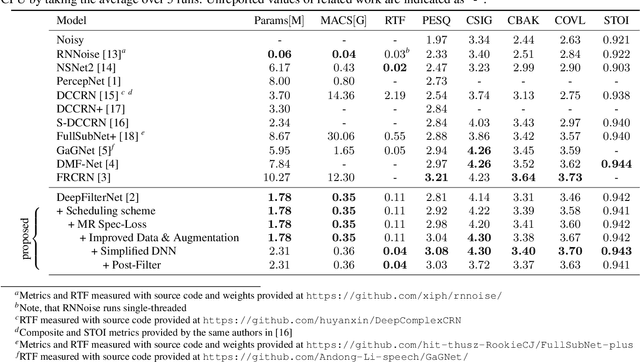
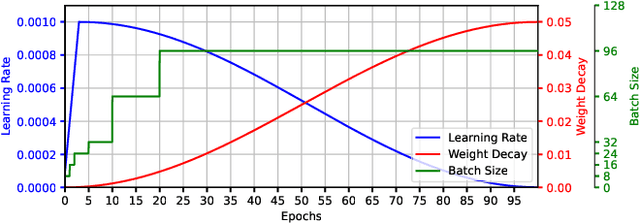
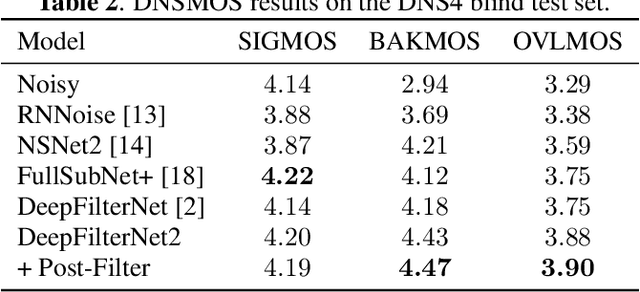
Deep learning-based speech enhancement has seen huge improvements and recently also expanded to full band audio (48 kHz). However, many approaches have a rather high computational complexity and require big temporal buffers for real time usage e.g. due to temporal convolutions or attention. Both make those approaches not feasible on embedded devices. This work further extends DeepFilterNet, which exploits harmonic structure of speech allowing for efficient speech enhancement (SE). Several optimizations in the training procedure, data augmentation, and network structure result in state-of-the-art SE performance while reducing the real-time factor to 0.04 on a notebook Core-i5 CPU. This makes the algorithm applicable to run on embedded devices in real-time. The DeepFilterNet framework can be obtained under an open source license.
DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
Oct 11, 2021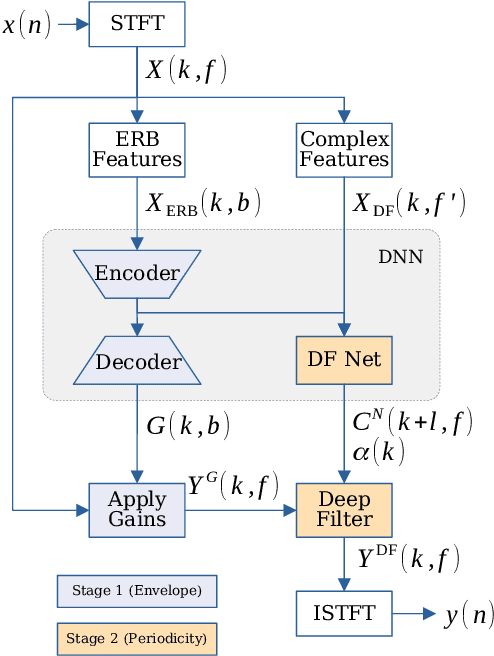
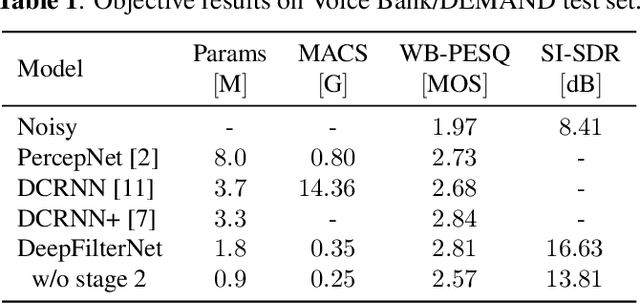
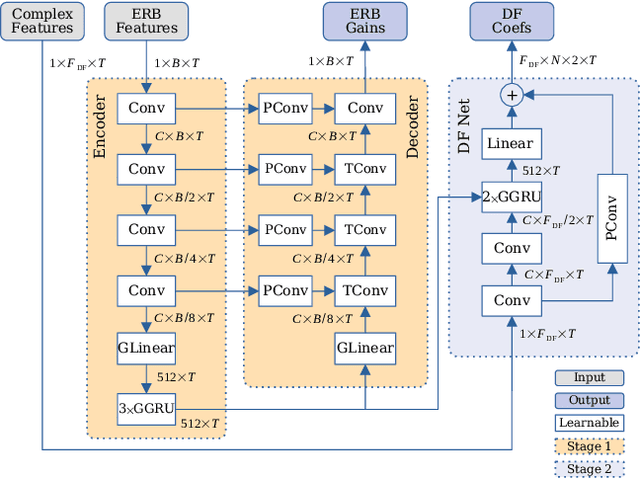
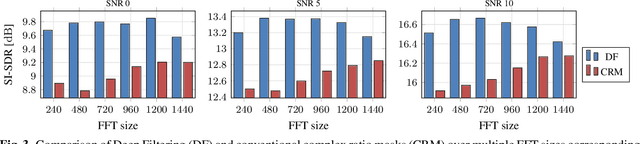
Complex-valued processing has brought deep learning-based speech enhancement and signal extraction to a new level. Typically, the process is based on a time-frequency (TF) mask which is applied to a noisy spectrogram, while complex masks (CM) are usually preferred over real-valued masks due to their ability to modify the phase. Recent work proposed to use a complex filter instead of a point-wise multiplication with a mask. This allows to incorporate information from previous and future time steps exploiting local correlations within each frequency band. In this work, we propose DeepFilterNet, a two stage speech enhancement framework utilizing deep filtering. First, we enhance the spectral envelope using ERB-scaled gains modeling the human frequency perception. The second stage employs deep filtering to enhance the periodic components of speech. Additionally to taking advantage of perceptual properties of speech, we enforce network sparsity via separable convolutions and extensive grouping in linear and recurrent layers to design a low complexity architecture. We further show that our two stage deep filtering approach outperforms complex masks over a variety of frequency resolutions and latencies and demonstrate convincing performance compared to other state-of-the-art models.
Ubicomp Digital 2020 -- Handwriting classification using a convolutional recurrent network
Aug 03, 2020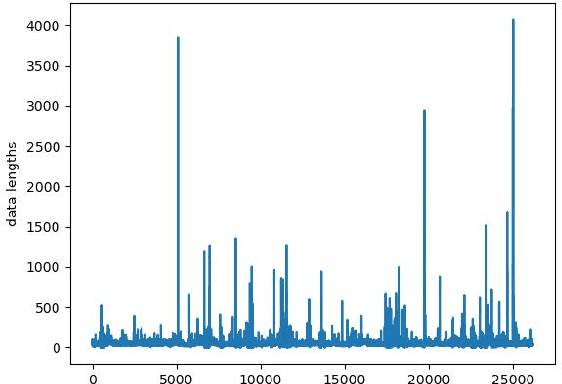
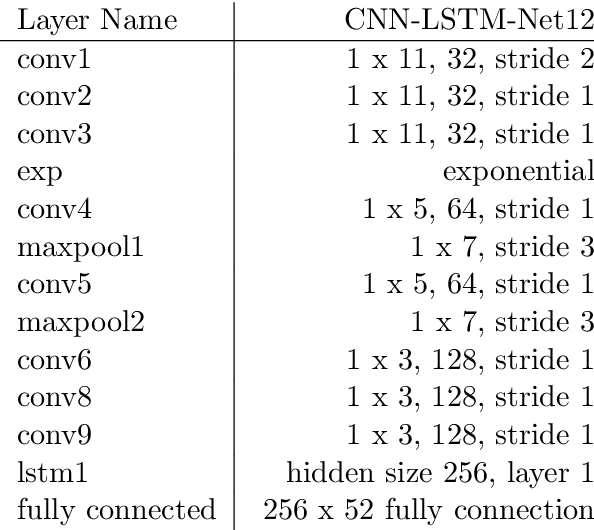
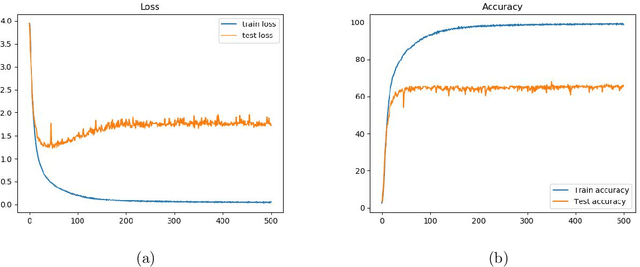
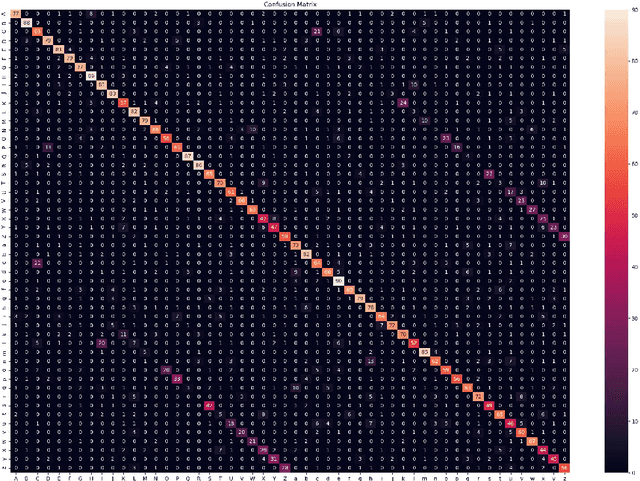
The Ubicomp Digital 2020 -- Time Series Classification Challenge from STABILO is a challenge about multi-variate time series classification. The data collected from 100 volunteer writers, and contains 15 features measured with multiple sensors on a pen. In this paper,we use a neural network to classify the data into 52 classes, that is lower and upper cases of Arabic letters. The proposed architecture of the neural network a is CNN-LSTM network. It combines convolutional neural network (CNN) for short term context with along short term memory layer (LSTM) for also long term dependencies. We reached an accuracy of 68% on our writer exclusive test set and64.6% on the blind challenge test set resulting in the second place.
CLCNet: Deep learning-based Noise Reduction for Hearing Aids using Complex Linear Coding
Jan 28, 2020
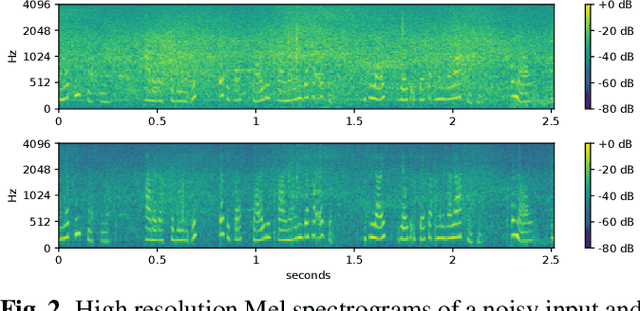
Noise reduction is an important part of modern hearing aids and is included in most commercially available devices. Deep learning-based state-of-the-art algorithms, however, either do not consider real-time and frequency resolution constrains or result in poor quality under very noisy conditions. To improve monaural speech enhancement in noisy environments, we propose CLCNet, a framework based on complex valued linear coding. First, we define complex linear coding (CLC) motivated by linear predictive coding (LPC) that is applied in the complex frequency domain. Second, we propose a framework that incorporates complex spectrogram input and coefficient output. Third, we define a parametric normalization for complex valued spectrograms that complies with low-latency and on-line processing. Our CLCNet was evaluated on a mixture of the EUROM database and a real-world noise dataset recorded with hearing aids and compared to traditional real-valued Wiener-Filter gains.