 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Frame Filtering for Hearing Aids
May 14, 2023Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep filtering (DF) recently demonstrated its capabilities for low-latency scenarios like hearing aids with its complex multi-frame (MF) filter. Alternatively, the complex filter can be estimated via an MF minimum variance distortionless response (MVDR), or MF Wiener filter (WF). Previous studies have shown that incorporating algorithm domain knowledge using an MVDR filter might be beneficial compared to the direct filter estimation via DF. In this work, we compare the usage of various multi-frame filters such as DF, MF-MVDR, or MF-WF for HAs. We assess different covariance estimation methods for both MF-MVDR and MF-WF and objectively demonstrate an improved performance compared to direct DF estimation, significantly outperforming related work while improving the runtime performance.
DeepFilterNet: Perceptually Motivated Real-Time Speech Enhancement
May 14, 2023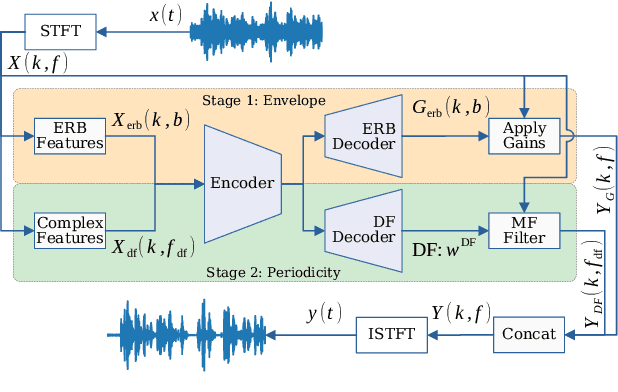


Multi-frame algorithms for single-channel speech enhancement are able to take advantage from short-time correlations within the speech signal. Deep Filtering (DF) was proposed to directly estimate a complex filter in frequency domain to take advantage of these correlations. In this work, we present a real-time speech enhancement demo using DeepFilterNet. DeepFilterNet's efficiency is enabled by exploiting domain knowledge of speech production and psychoacoustic perception. Our model is able to match state-of-the-art speech enhancement benchmarks while achieving a real-time-factor of 0.19 on a single threaded notebook CPU. The framework as well as pretrained weights have been published under an open source license.
DeepFilterNet2: Towards Real-Time Speech Enhancement on Embedded Devices for Full-Band Audio
May 11, 2022
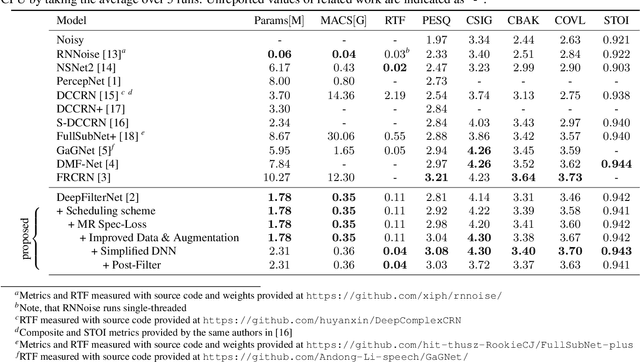
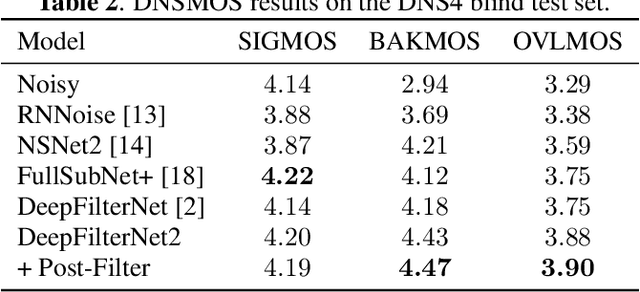
Deep learning-based speech enhancement has seen huge improvements and recently also expanded to full band audio (48 kHz). However, many approaches have a rather high computational complexity and require big temporal buffers for real time usage e.g. due to temporal convolutions or attention. Both make those approaches not feasible on embedded devices. This work further extends DeepFilterNet, which exploits harmonic structure of speech allowing for efficient speech enhancement (SE). Several optimizations in the training procedure, data augmentation, and network structure result in state-of-the-art SE performance while reducing the real-time factor to 0.04 on a notebook Core-i5 CPU. This makes the algorithm applicable to run on embedded devices in real-time. The DeepFilterNet framework can be obtained under an open source license.
DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
Oct 11, 2021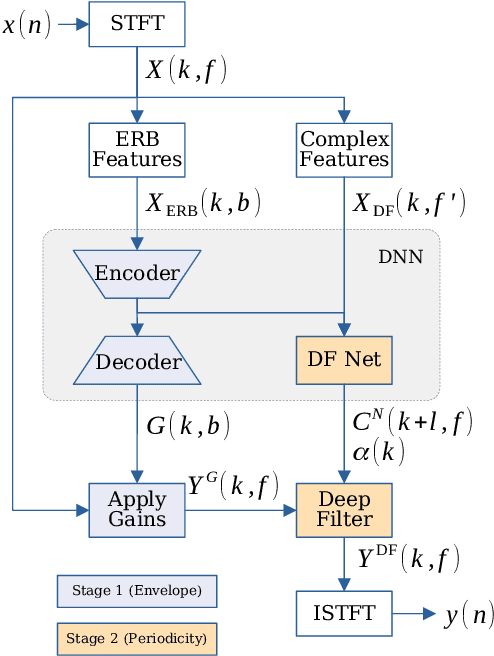
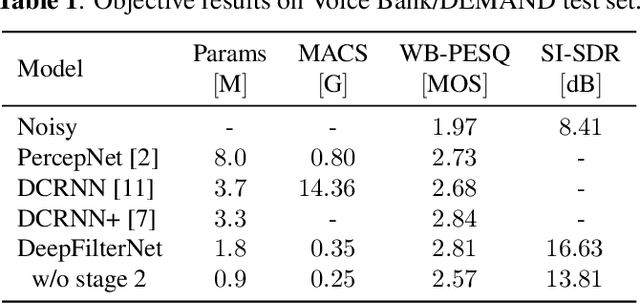
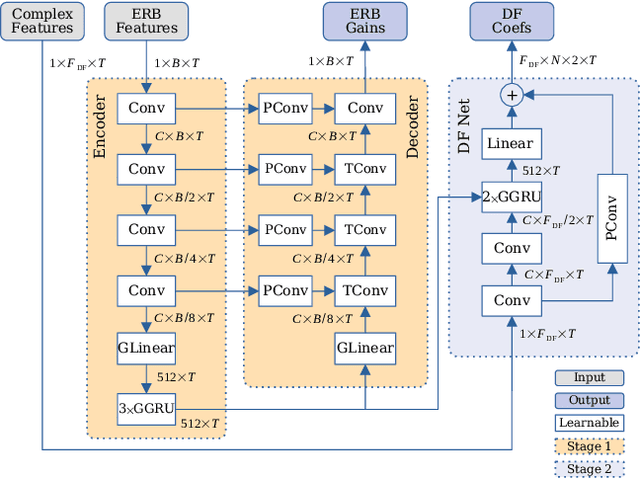
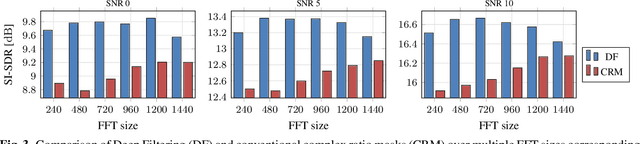
Complex-valued processing has brought deep learning-based speech enhancement and signal extraction to a new level. Typically, the process is based on a time-frequency (TF) mask which is applied to a noisy spectrogram, while complex masks (CM) are usually preferred over real-valued masks due to their ability to modify the phase. Recent work proposed to use a complex filter instead of a point-wise multiplication with a mask. This allows to incorporate information from previous and future time steps exploiting local correlations within each frequency band. In this work, we propose DeepFilterNet, a two stage speech enhancement framework utilizing deep filtering. First, we enhance the spectral envelope using ERB-scaled gains modeling the human frequency perception. The second stage employs deep filtering to enhance the periodic components of speech. Additionally to taking advantage of perceptual properties of speech, we enforce network sparsity via separable convolutions and extensive grouping in linear and recurrent layers to design a low complexity architecture. We further show that our two stage deep filtering approach outperforms complex masks over a variety of frequency resolutions and latencies and demonstrate convincing performance compared to other state-of-the-art models.
Measuring the Data Efficiency of Deep Learning Methods
Jul 03, 2019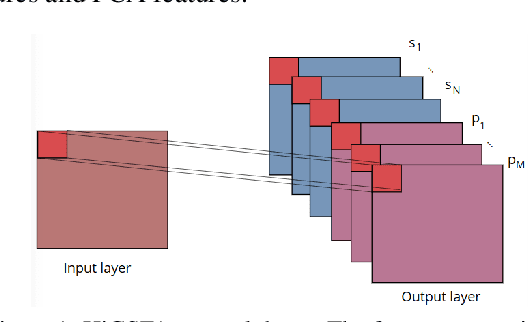
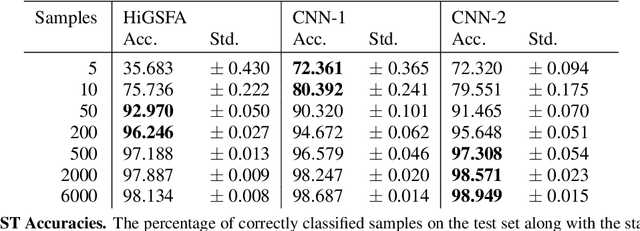
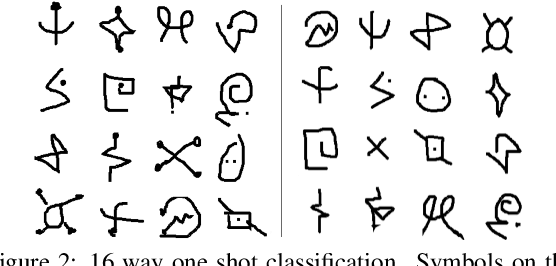
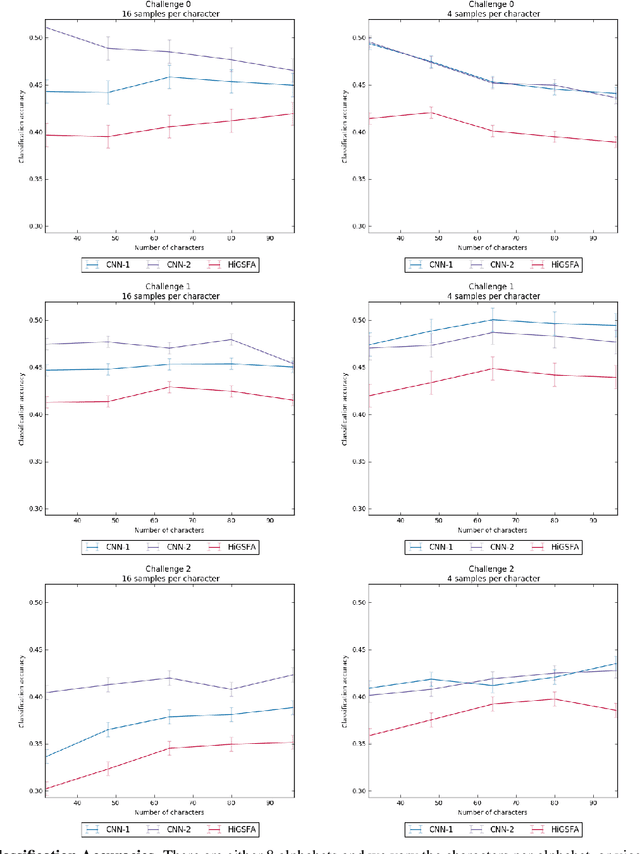
In this paper, we propose a new experimental protocol and use it to benchmark the data efficiency --- performance as a function of training set size --- of two deep learning algorithms, convolutional neural networks (CNNs) and hierarchical information-preserving graph-based slow feature analysis (HiGSFA), for tasks in classification and transfer learning scenarios. The algorithms are trained on different-sized subsets of the MNIST and Omniglot data sets. HiGSFA outperforms standard CNN networks when the models are trained on 50 and 200 samples per class for MNIST classification. In other cases, the CNNs perform better. The results suggest that there are cases where greedy, locally optimal bottom-up learning is equally or more powerful than global gradient-based learning.
* 8 pages
Improved graph-based SFA: Information preservation complements the slowness principle
Jan 15, 2016



Slow feature analysis (SFA) is an unsupervised-learning algorithm that extracts slowly varying features from a multi-dimensional time series. A supervised extension to SFA for classification and regression is graph-based SFA (GSFA). GSFA is based on the preservation of similarities, which are specified by a graph structure derived from the labels. It has been shown that hierarchical GSFA (HGSFA) allows learning from images and other high-dimensional data. The feature space spanned by HGSFA is complex due to the composition of the nonlinearities of the nodes in the network. However, we show that the network discards useful information prematurely before it reaches higher nodes, resulting in suboptimal global slowness and an under-exploited feature space. To counteract these problems, we propose an extension called hierarchical information-preserving GSFA (HiGSFA), where information preservation complements the slowness-maximization goal. We build a 10-layer HiGSFA network to estimate human age from facial photographs of the MORPH-II database, achieving a mean absolute error of 3.50 years, improving the state-of-the-art performance. HiGSFA and HGSFA support multiple-labels and offer a rich feature space, feed-forward training, and linear complexity in the number of samples and dimensions. Furthermore, HiGSFA outperforms HGSFA in terms of feature slowness, estimation accuracy and input reconstruction, giving rise to a promising hierarchical supervised-learning approach.
Theoretical Analysis of the Optimal Free Responses of Graph-Based SFA for the Design of Training Graphs
Sep 28, 2015



Slow feature analysis (SFA) is an unsupervised learning algorithm that extracts slowly varying features from a time series. Graph-based SFA (GSFA) is a supervised extension that can solve regression problems if followed by a post-processing regression algorithm. A training graph specifies arbitrary connections between the training samples. The connections in current graphs, however, only depend on the rank of the involved labels. Exploiting the exact label values makes further improvements in estimation accuracy possible. In this article, we propose the exact label learning (ELL) method to create a graph that codes the desired label explicitly, so that GSFA is able to extract a normalized version of it directly. The ELL method is used for three tasks: (1) We estimate gender from artificial images of human faces (regression) and show the advantage of coding additional labels, particularly skin color. (2) We analyze two existing graphs for regression. (3) We extract compact discriminative features to classify traffic sign images. When the number of output features is limited, a higher classification rate is obtained compared to a graph equivalent to nonlinear Fisher discriminant analysis. The method is versatile, directly supports multiple labels, and provides higher accuracy compared to current graphs for the problems considered.