 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Doubly Robust Learning for Causal Inference
Jun 02, 2024Doubly robust learning offers a robust framework for causal inference from observational data by integrating propensity score and outcome modeling. Despite its theoretical appeal, practical adoption remains limited due to perceived complexity and inaccessible software. This tutorial aims to demystify doubly robust methods and demonstrate their application using the EconML package. We provide an introduction to causal inference, discuss the principles of outcome modeling and propensity scores, and illustrate the doubly robust approach through simulated case studies. By simplifying the methodology and offering practical coding examples, we intend to make doubly robust learning accessible to researchers and practitioners in data science and statistics.
Visual processing in context of reinforcement learning
Aug 26, 2022
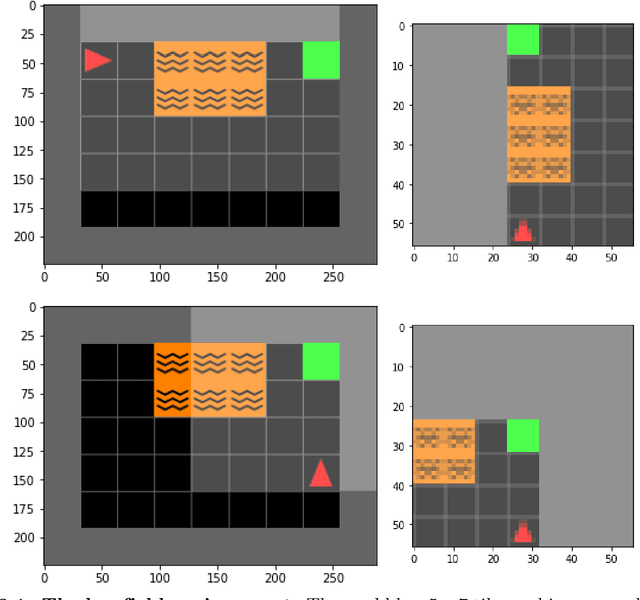
Although deep reinforcement learning (RL) has recently enjoyed many successes, its methods are still data inefficient, which makes solving numerous problems prohibitively expensive in terms of data. We aim to remedy this by taking advantage of the rich supervisory signal in unlabeled data for learning state representations. This thesis introduces three different representation learning algorithms that have access to different subsets of the data sources that traditional RL algorithms use: (i) GRICA is inspired by independent component analysis (ICA) and trains a deep neural network to output statistically independent features of the input. GrICA does so by minimizing the mutual information between each feature and the other features. Additionally, GrICA only requires an unsorted collection of environment states. (ii) Latent Representation Prediction (LARP) requires more context: in addition to requiring a state as an input, it also needs the previous state and an action that connects them. This method learns state representations by predicting the representation of the environment's next state given a current state and action. The predictor is used with a graph search algorithm. (iii) RewPred learns a state representation by training a deep neural network to learn a smoothed version of the reward function. The representation is used for preprocessing inputs to deep RL, while the reward predictor is used for reward shaping. This method needs only state-reward pairs from the environment for learning the representation. We discover that every method has their strengths and weaknesses, and conclude from our experiments that including unsupervised representation learning in RL problem-solving pipelines can speed up learning.
Reward prediction for representation learning and reward shaping
May 07, 2021
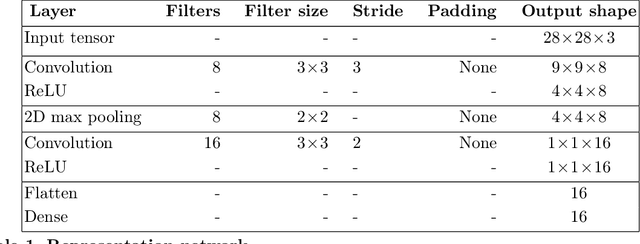
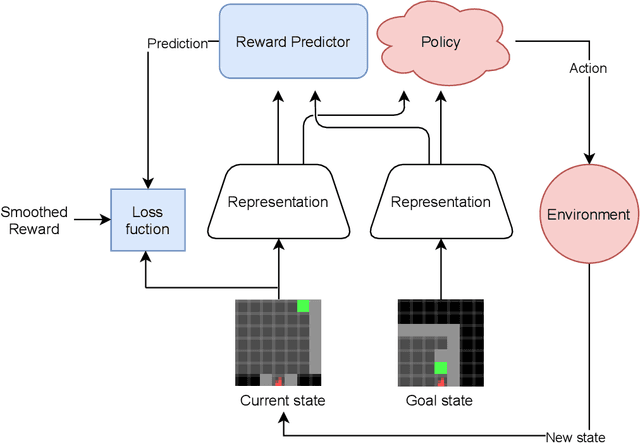

One of the fundamental challenges in reinforcement learning (RL) is the one of data efficiency: modern algorithms require a very large number of training samples, especially compared to humans, for solving environments with high-dimensional observations. The severity of this problem is increased when the reward signal is sparse. In this work, we propose learning a state representation in a self-supervised manner for reward prediction. The reward predictor learns to estimate either a raw or a smoothed version of the true reward signal in environment with a single, terminating, goal state. We augment the training of out-of-the-box RL agents by shaping the reward using our reward predictor during policy learning. Using our representation for preprocessing high-dimensional observations, as well as using the predictor for reward shaping, is shown to significantly enhance Actor Critic using Kronecker-factored Trust Region and Proximal Policy Optimization in single-goal environments with visual inputs.
Latent Representation Prediction Networks
Sep 20, 2020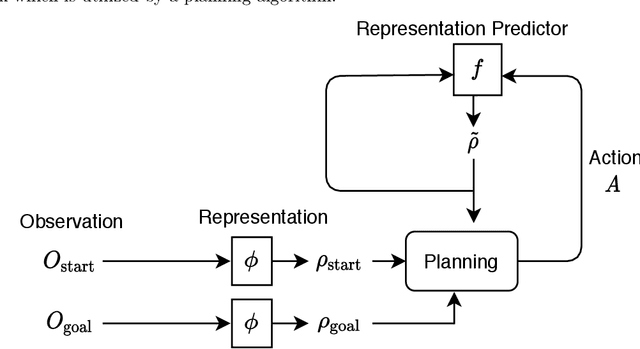
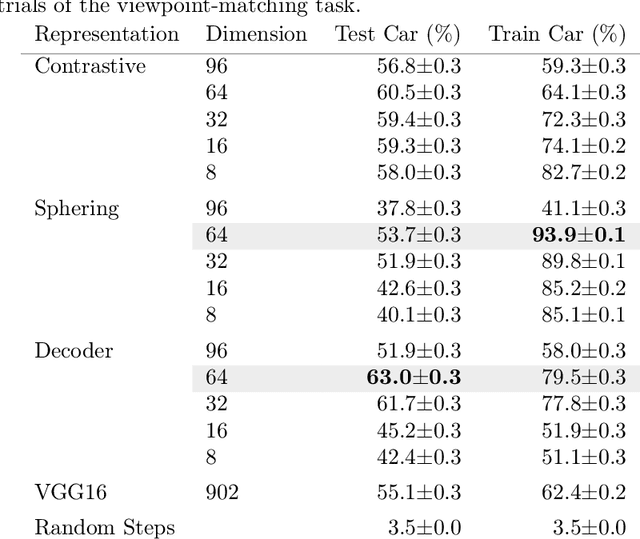
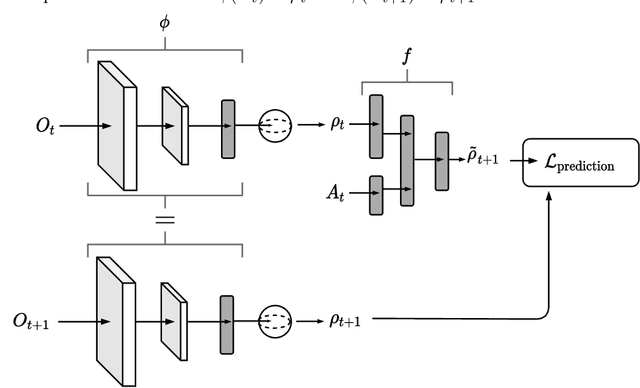

Deeply-learned planning methods are often based on learning representations that are optimized for unrelated tasks. For example, they might be trained on reconstructing the environment. These representations are then combined with predictor functions for simulating rollouts to navigate the environment. We find this principle of learning representations unsatisfying and propose to learn them such that they are directly optimized for the task at hand: to be maximally predictable for the predictor function. This results in representations that are by design optimal for the downstream task of planning, where the learned predictor function is used as a forward model. To this end, we propose a new way of jointly learning this representation along with the prediction function, a system we dub Latent Representation Prediction Network (LARP). The prediction function is used as a forward model for search on a graph in a viewpoint-matching task and the representation learned to maximize predictability is found to outperform a pre-trained representation. Our approach is shown to be more sample-efficient than standard reinforcement learning methods and our learned representation transfers successfully to dissimilar objects.
Measuring the Data Efficiency of Deep Learning Methods
Jul 03, 2019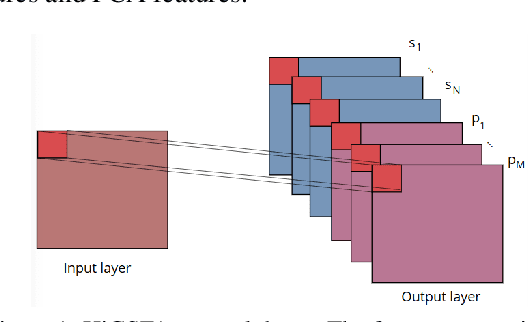
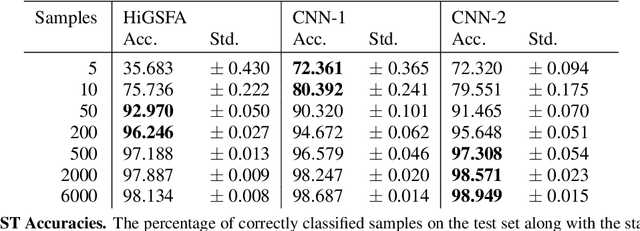
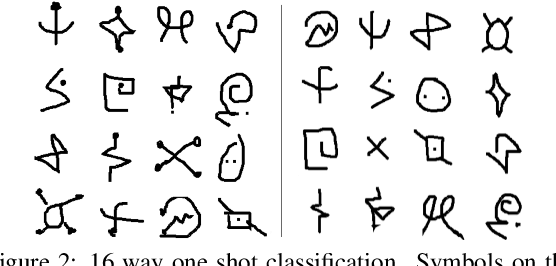
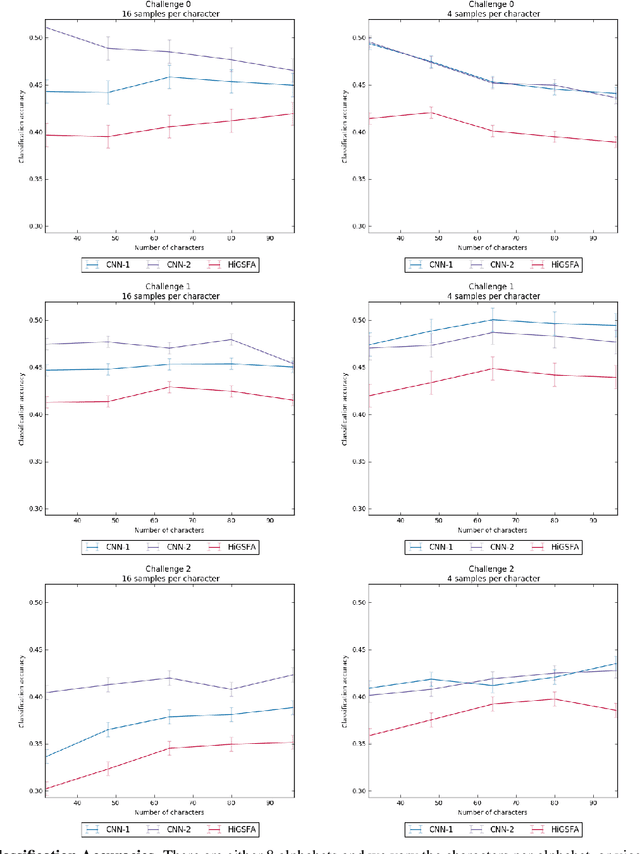
In this paper, we propose a new experimental protocol and use it to benchmark the data efficiency --- performance as a function of training set size --- of two deep learning algorithms, convolutional neural networks (CNNs) and hierarchical information-preserving graph-based slow feature analysis (HiGSFA), for tasks in classification and transfer learning scenarios. The algorithms are trained on different-sized subsets of the MNIST and Omniglot data sets. HiGSFA outperforms standard CNN networks when the models are trained on 50 and 200 samples per class for MNIST classification. In other cases, the CNNs perform better. The results suggest that there are cases where greedy, locally optimal bottom-up learning is equally or more powerful than global gradient-based learning.
* 8 pages
Learning gradient-based ICA by neurally estimating mutual information
Apr 22, 2019
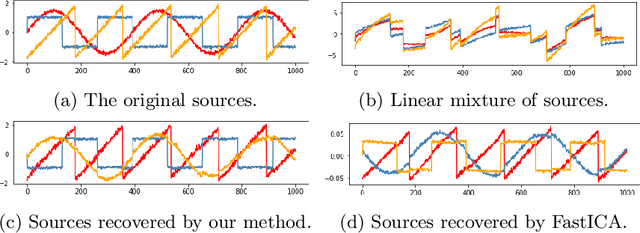
Several methods of estimating the mutual information of random variables have been developed in recent years. They can prove valuable for novel approaches to learning statistically independent features. In this paper, we use one of these methods, a mutual information neural estimation (MINE) network, to present a proof-of-concept of how a neural network can perform linear ICA. We minimize the mutual information, as estimated by a MINE network, between the output units of a differentiable encoder network. This is done by simple alternate optimization of the two networks. The method is shown to get a qualitatively equal solution to FastICA on blind-source-separation of noisy sources.
Gradient-based Training of Slow Feature Analysis by Differentiable Approximate Whitening
Aug 27, 2018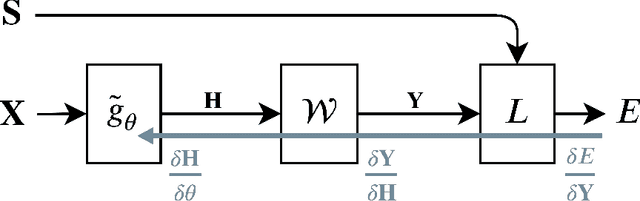

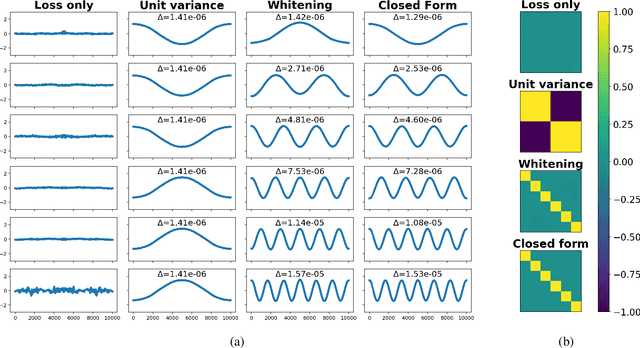
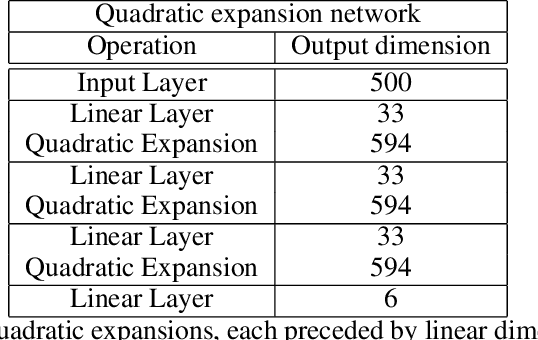
This paper proposes Power Slow Feature Analysis, a gradient-based method to extract temporally-slow features from a high-dimensional input stream that varies on a faster time-scale, and a variant of Slow Feature Analysis (SFA). While displaying performance comparable to hierarchical extensions to the SFA algorithm, such as Hierarchical Slow Feature Analysis, for a small number of output-features, our algorithm allows end-to-end training of arbitrary differentiable approximators (e.g., deep neural networks). We provide experimental evidence that PowerSFA is able to extract meaningful and informative low-dimensional features in the case of a) synthetic low-dimensional data, b) visual data, and also for c) a general dataset for which symmetric non-temporal relations between points can be defined.