 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual processing in context of reinforcement learning
Paper and Code
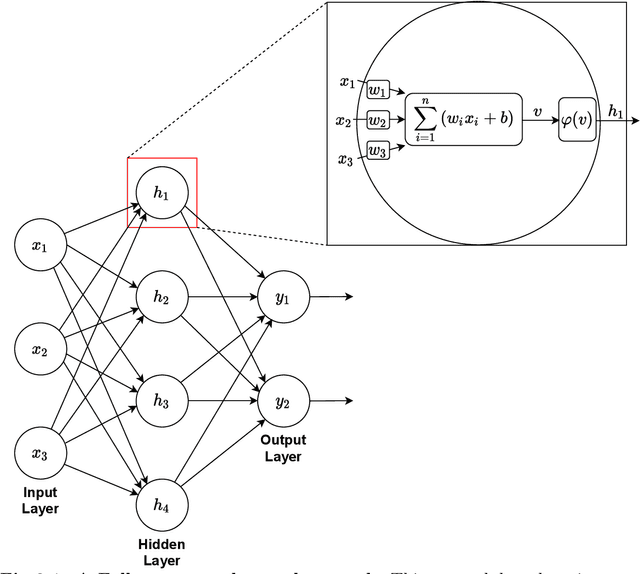
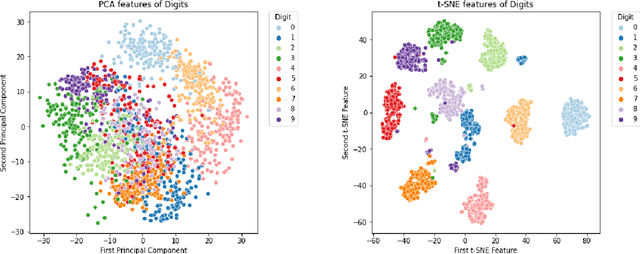
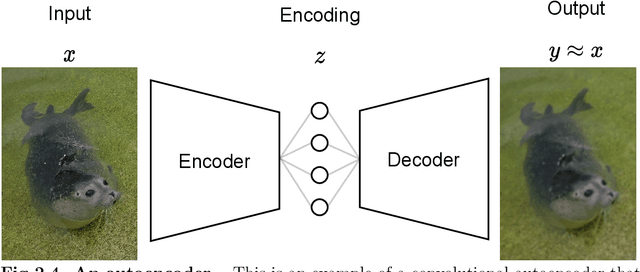
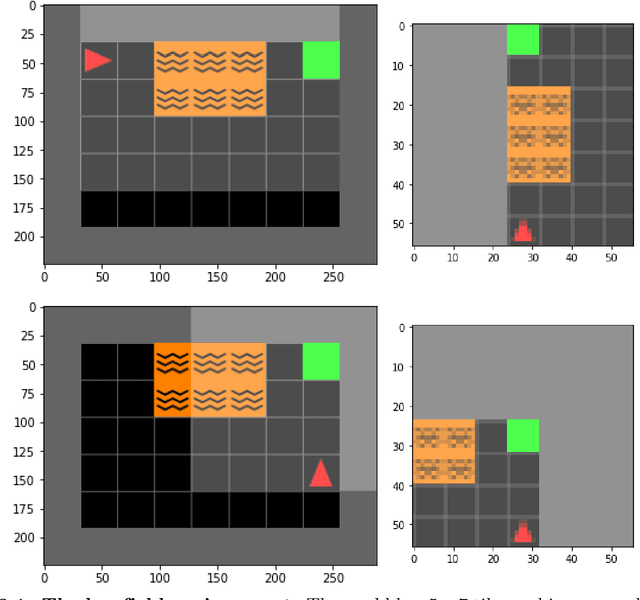
Although deep reinforcement learning (RL) has recently enjoyed many successes, its methods are still data inefficient, which makes solving numerous problems prohibitively expensive in terms of data. We aim to remedy this by taking advantage of the rich supervisory signal in unlabeled data for learning state representations. This thesis introduces three different representation learning algorithms that have access to different subsets of the data sources that traditional RL algorithms use: (i) GRICA is inspired by independent component analysis (ICA) and trains a deep neural network to output statistically independent features of the input. GrICA does so by minimizing the mutual information between each feature and the other features. Additionally, GrICA only requires an unsorted collection of environment states. (ii) Latent Representation Prediction (LARP) requires more context: in addition to requiring a state as an input, it also needs the previous state and an action that connects them. This method learns state representations by predicting the representation of the environment's next state given a current state and action. The predictor is used with a graph search algorithm. (iii) RewPred learns a state representation by training a deep neural network to learn a smoothed version of the reward function. The representation is used for preprocessing inputs to deep RL, while the reward predictor is used for reward shaping. This method needs only state-reward pairs from the environment for learning the representation. We discover that every method has their strengths and weaknesses, and conclude from our experiments that including unsupervised representation learning in RL problem-solving pipelines can speed up learning.