 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFilterNet2: Towards Real-Time Speech Enhancement on Embedded Devices for Full-Band Audio
Paper and Code

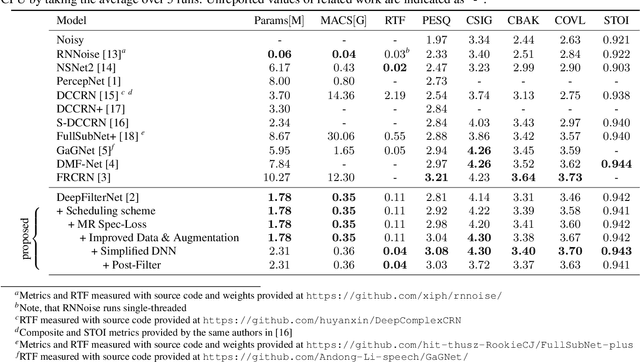
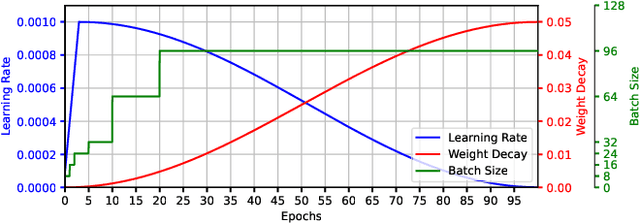
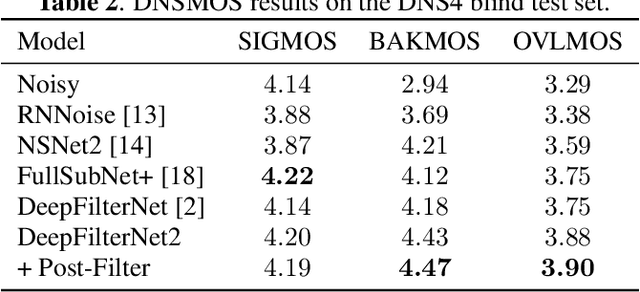
Deep learning-based speech enhancement has seen huge improvements and recently also expanded to full band audio (48 kHz). However, many approaches have a rather high computational complexity and require big temporal buffers for real time usage e.g. due to temporal convolutions or attention. Both make those approaches not feasible on embedded devices. This work further extends DeepFilterNet, which exploits harmonic structure of speech allowing for efficient speech enhancement (SE). Several optimizations in the training procedure, data augmentation, and network structure result in state-of-the-art SE performance while reducing the real-time factor to 0.04 on a notebook Core-i5 CPU. This makes the algorithm applicable to run on embedded devices in real-time. The DeepFilterNet framework can be obtained under an open source license.