 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScriboora: Rethinking Human Pose Forecasting
Nov 19, 2025
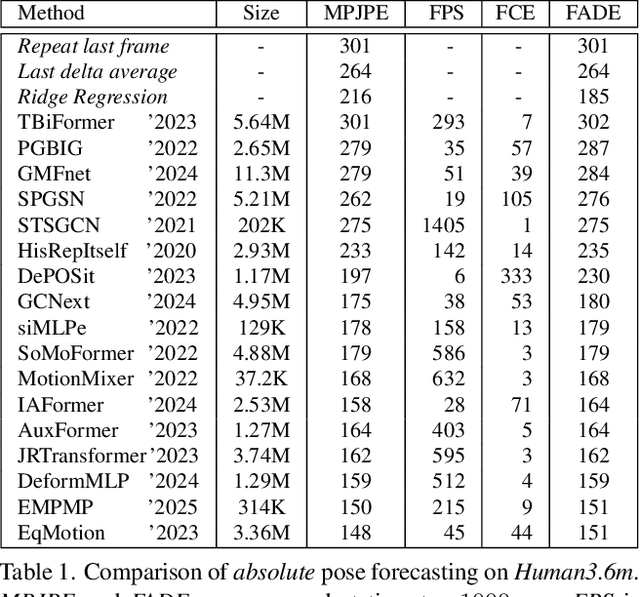
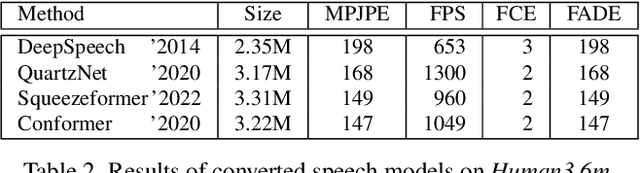
Human pose forecasting predicts future poses based on past observations, and has many significant applications in areas such as action recognition, autonomous driving or human-robot interaction. This paper evaluates a wide range of pose forecasting algorithms in the task of absolute pose forecasting, revealing many reproducibility issues, and provides a unified training and evaluation pipeline. After drawing a high-level analogy to the task of speech understanding, it is shown that recent speech models can be efficiently adapted to the task of pose forecasting, and improve current state-of-the-art performance. At last the robustness of the models is evaluated, using noisy joint coordinates obtained from a pose estimator model, to reflect a realistic type of noise, which is more close to real-world applications. For this a new dataset variation is introduced, and it is shown that estimated poses result in a substantial performance degradation, and how much of it can be recovered again by unsupervised finetuning.
RapidPoseTriangulation: Multi-view Multi-person Whole-body Human Pose Triangulation in a Millisecond
Mar 27, 2025



The integration of multi-view imaging and pose estimation represents a significant advance in computer vision applications, offering new possibilities for understanding human movement and interactions. This work presents a new algorithm that improves multi-view multi-person pose estimation, focusing on fast triangulation speeds and good generalization capabilities. The approach extends to whole-body pose estimation, capturing details from facial expressions to finger movements across multiple individuals and viewpoints. Adaptability to different settings is demonstrated through strong performance across unseen datasets and configurations. To support further progress in this field, all of this work is publicly accessible.
SimpleDepthPose: Fast and Reliable Human Pose Estimation with RGBD-Images
Jan 30, 2025
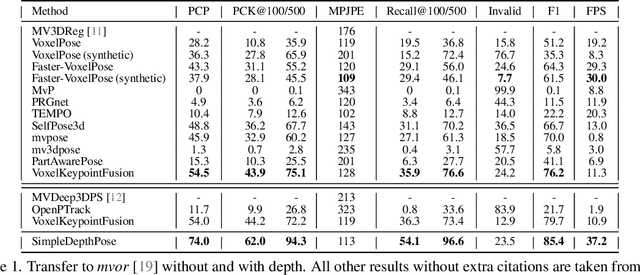


In the rapidly advancing domain of computer vision, accurately estimating the poses of multiple individuals from various viewpoints remains a significant challenge, especially when reliability is a key requirement. This paper introduces a novel algorithm that excels in multi-view, multi-person pose estimation by incorporating depth information. An extensive evaluation demonstrates that the proposed algorithm not only generalizes well to unseen datasets, and shows a fast runtime performance, but also is adaptable to different keypoints. To support further research, all of the work is publicly accessible.
VoxelKeypointFusion: Generalizable Multi-View Multi-Person Pose Estimation
Oct 24, 2024



In the rapidly evolving field of computer vision, the task of accurately estimating the poses of multiple individuals from various viewpoints presents a formidable challenge, especially if the estimations should be reliable as well. This work presents an extensive evaluation of the generalization capabilities of multi-view multi-person pose estimators to unseen datasets and presents a new algorithm with strong performance in this task. It also studies the improvements by additionally using depth information. Since the new approach can not only generalize well to unseen datasets, but also to different keypoints, the first multi-view multi-person whole-body estimator is presented. To support further research on those topics, all of the work is publicly accessible.
Towards Automated COVID-19 Presence and Severity Classification
May 15, 2023COVID-19 presence classification and severity prediction via (3D) thorax computed tomography scans have become important tasks in recent times. Especially for capacity planning of intensive care units, predicting the future severity of a COVID-19 patient is crucial. The presented approach follows state-of-theart techniques to aid medical professionals in these situations. It comprises an ensemble learning strategy via 5-fold cross-validation that includes transfer learning and combines pre-trained 3D-versions of ResNet34 and DenseNet121 for COVID19 classification and severity prediction respectively. Further, domain-specific preprocessing was applied to optimize model performance. In addition, medical information like the infection-lung-ratio, patient age, and sex were included. The presented model achieves an AUC of 79.0% to predict COVID-19 severity, and 83.7% AUC to classify the presence of an infection, which is comparable with other currently popular methods. This approach is implemented using the AUCMEDI framework and relies on well-known network architectures to ensure robustness and reproducibility.
Finstreder: Simple and fast Spoken Language Understanding with Finite State Transducers using modern Speech-to-Text models
Jun 29, 2022
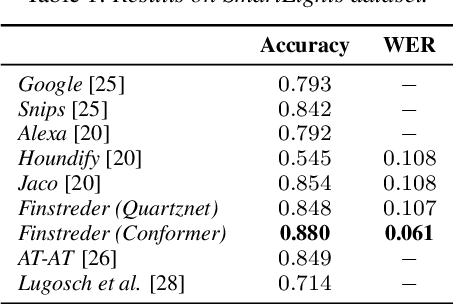
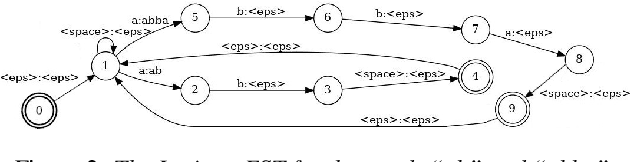
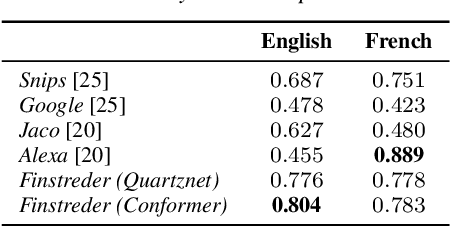
In Spoken Language Understanding (SLU) the task is to extract important information from audio commands, like the intent of what a user wants the system to do and special entities like locations or numbers. This paper presents a simple method for embedding intents and entities into Finite State Transducers, and, in combination with a pretrained general-purpose Speech-to-Text model, allows building SLU-models without any additional training. Building those models is very fast and only takes a few seconds. It is also completely language independent. With a comparison on different benchmarks it is shown that this method can outperform multiple other, more resource demanding SLU approaches.
Scribosermo: Fast Speech-to-Text models for German and other Languages
Oct 15, 2021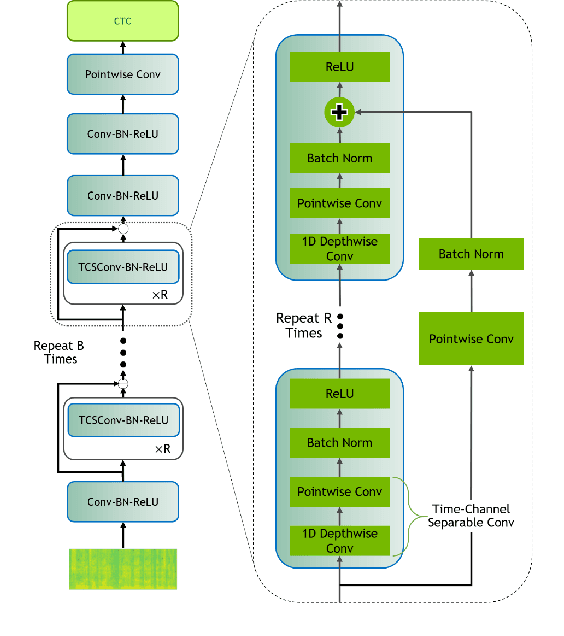


Recent Speech-to-Text models often require a large amount of hardware resources and are mostly trained in English. This paper presents Speech-to-Text models for German, as well as for Spanish and French with special features: (a) They are small and run in real-time on microcontrollers like a RaspberryPi. (b) Using a pretrained English model, they can be trained on consumer-grade hardware with a relatively small dataset. (c) The models are competitive with other solutions and outperform them in German. In this respect, the models combine advantages of other approaches, which only include a subset of the presented features. Furthermore, the paper provides a new library for handling datasets, which is focused on easy extension with additional datasets and shows an optimized way for transfer-learning new languages using a pretrained model from another language with a similar alphabet.
Opportunities and Limitations of Mixed Reality Holograms in Industrial Robotics
Jan 22, 2020
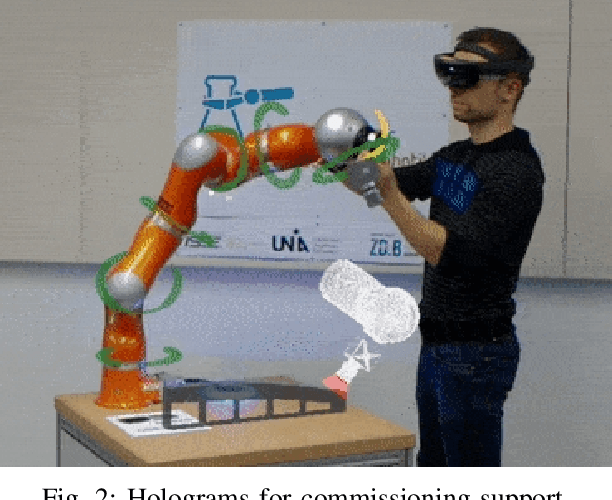
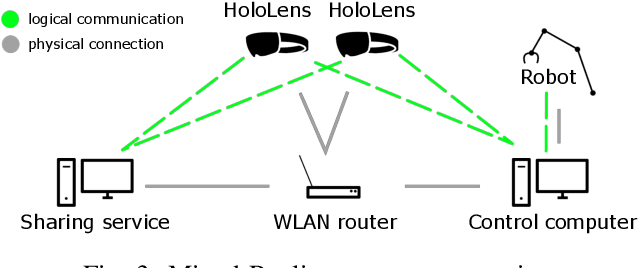
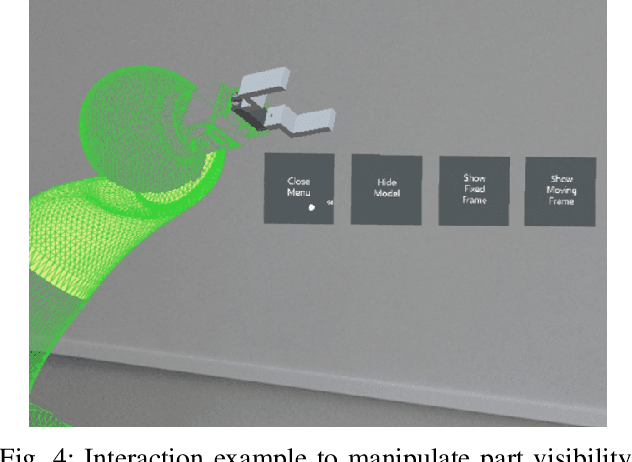
This paper introduces two case studies combining the field of industrial robotics with Mixed Reality (MR). The goal of those case studies is to get a better understanding of how MR can be useful and what are the limitations. The first case study describes an approach to visualize the digital twin of a robot arm. The second case study aims at facilitating the commissioning of industrial robots. Furthermore, this paper reports the experiences gained by implementing those two scenarios and discusses the limitations.
A Graphical Language for Real-Time Critical Robot Commands
Mar 27, 2013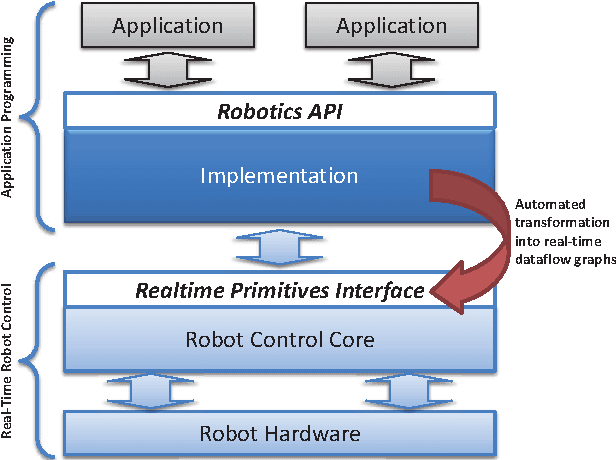
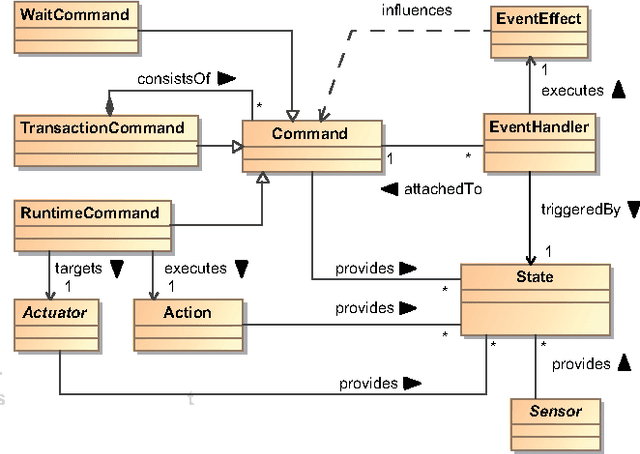
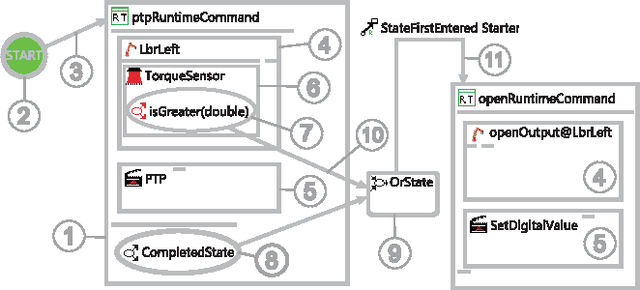
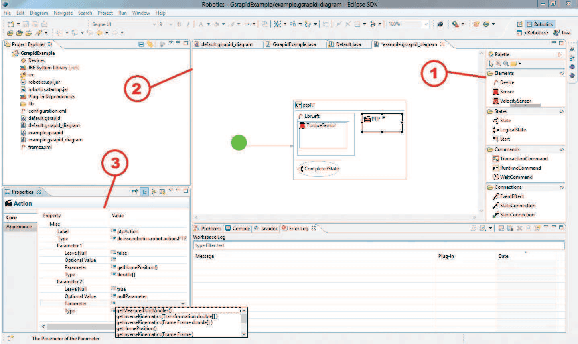
Industrial robotics is characterized by sophisticated mechanical components and highly-developed real-time control algorithms. However, the efficient use of robotic systems is very much limited by existing proprietary programming methods. In the research project SoftRobot, a software architecture was developed that enables the programming of complex real-time critical robot tasks with an object-oriented general purpose language. On top of this architecture, a graphical language was developed to ease the specification of complex robot commands, which can then be used as part of robot application workflows. This paper gives an overview about the design and implementation of this graphical language and illustrates its usefulness with some examples.
On reverse-engineering the KUKA Robot Language
Sep 25, 2010
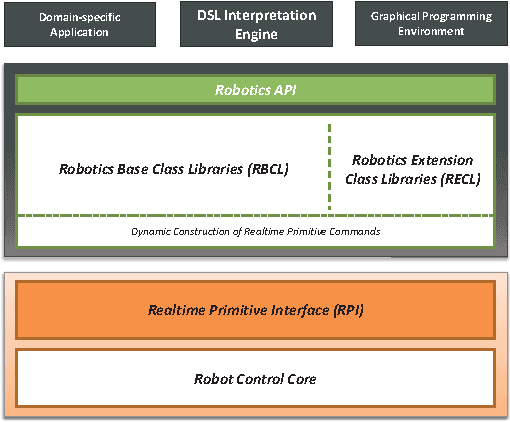
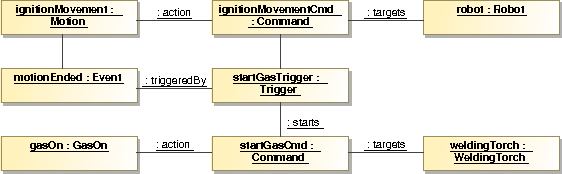
Most commercial manufacturers of industrial robots require their robots to be programmed in a proprietary language tailored to the domain - a typical domain-specific language (DSL). However, these languages oftentimes suffer from shortcomings such as controller-specific design, limited expressiveness and a lack of extensibility. For that reason, we developed the extensible Robotics API for programming industrial robots on top of a general-purpose language. Although being a very flexible approach to programming industrial robots, a fully-fledged language can be too complex for simple tasks. Additionally, legacy support for code written in the original DSL has to be maintained. For these reasons, we present a lightweight implementation of a typical robotic DSL, the KUKA Robot Language (KRL), on top of our Robotics API. This work deals with the challenges in reverse-engineering the language and mapping its specifics to the Robotics API. We introduce two different approaches of interpreting and executing KRL programs: tree-based and bytecode-based interpretation.