Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinstreder: Simple and fast Spoken Language Understanding with Finite State Transducers using modern Speech-to-Text models
Paper and Code
Jun 29, 2022
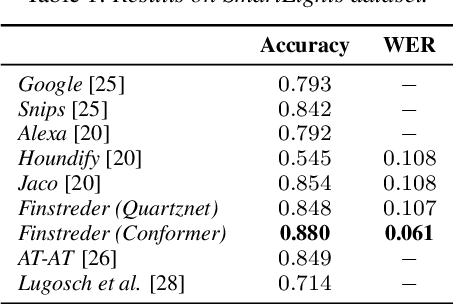
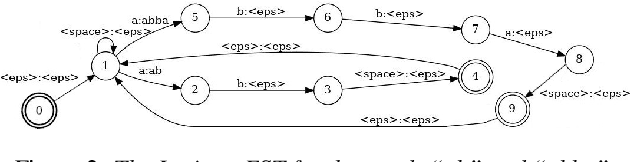
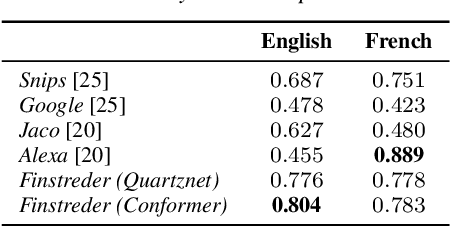
In Spoken Language Understanding (SLU) the task is to extract important information from audio commands, like the intent of what a user wants the system to do and special entities like locations or numbers. This paper presents a simple method for embedding intents and entities into Finite State Transducers, and, in combination with a pretrained general-purpose Speech-to-Text model, allows building SLU-models without any additional training. Building those models is very fast and only takes a few seconds. It is also completely language independent. With a comparison on different benchmarks it is shown that this method can outperform multiple other, more resource demanding SLU approaches.
View paper on