 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing voice analysis as an early indicator of risk for depression in young adults
Nov 18, 2024



Increasingly frequent publications in the literature report voice quality differences between depressed patients and controls. Here, we examine the possibility of using voice analysis as an early warning signal for the development of emotion disturbances in young adults. As part of a major interdisciplinary European research project in four countries (ECoWeB), examining the effects of web-based prevention programs to reduce the risk for depression in young adults, we analyzed a large number of acoustic voice characteristics in vocal reports of emotions experienced by the participants on a specific day. We were able to identify a number of significant differences in acoustic cues, particularly with respect to the energy distribution in the voice spectrum, encouraging further research efforts to develop promising non-obtrusive risk indicators in the normal speaking voice. This is particularly important in the case of young adults who are less likely to exhibit standard risk factors for depression such as negative life experiences.
Prosodic entrainment in dialog acts
Oct 30, 2018



We examined prosodic entrainment in spoken dialogs separately for several dialog acts in cooperative and competitive games. Entrainment was measured for intonation features derived from a superpositional intonation stylization as well as for rhythm features. The found differences can be related to the cooperative or competitive nature of the game, as well as to dialog act properties as its intrinsic authority, supportiveness and distributional characteristics. In cooperative games dialog acts with a high authority given by knowledge and with a high frequency showed the most entrainment. The results are discussed amongst others with respect to the degree of active entrainment control in cooperative behavior.
CoPaSul Manual - Contour-based parametric and superpositional intonation stylization
Oct 28, 2018



The purposes of the CoPaSul toolkit are (1) automatic prosodic annotation and (2) prosodic feature extraction from syllable to utterance level. CoPaSul stands for contour-based, parametric, superpositional intonation stylization. In this framework intonation is represented as a superposition of global and local contours that are described parametrically in terms of polynomial coefficients. On the global level (usually associated but not necessarily restricted to intonation phrases) the stylization serves to represent register in terms of time-varying F0 level and range. On the local level (e.g. accent groups), local contour shapes are described. From this parameterization several features related to prosodic boundaries and prominence can be derived. Furthermore, by coefficient clustering prosodic contour classes can be obtained in a bottom-up way. Next to the stylization-based feature extraction also standard F0 and energy measures (e.g. mean and variance) as well as rhythmic aspects can be calculated. At the current state automatic annotation comprises: segmentation into interpausal chunks, syllable nucleus extraction, and unsupervised localization of prosodic phrase boundaries and prominent syllables. F0 and partly also energy feature sets can be derived for: standard measurements (as median and IQR), register in terms of F0 level and range, prosodic boundaries, local contour shapes, bottom-up derived contour classes, Gestalt of accent groups in terms of their deviation from higher level prosodic units, as well as for rhythmic aspects quantifying the relation between F0 and energy contours and prosodic event rates.
Entrainment profiles: Comparison by gender, role, and feature set
May 29, 2018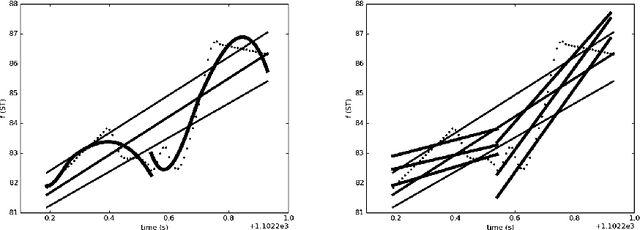
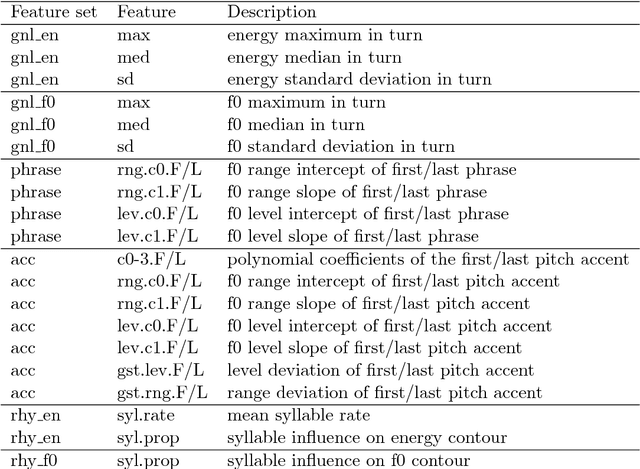
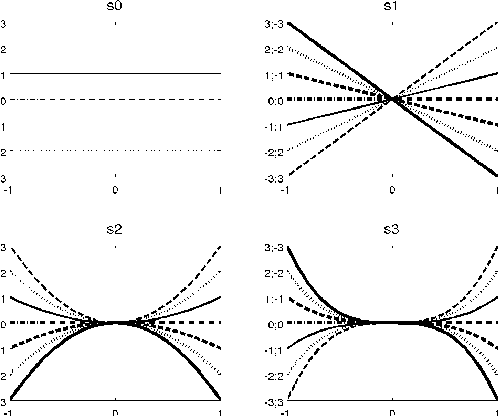
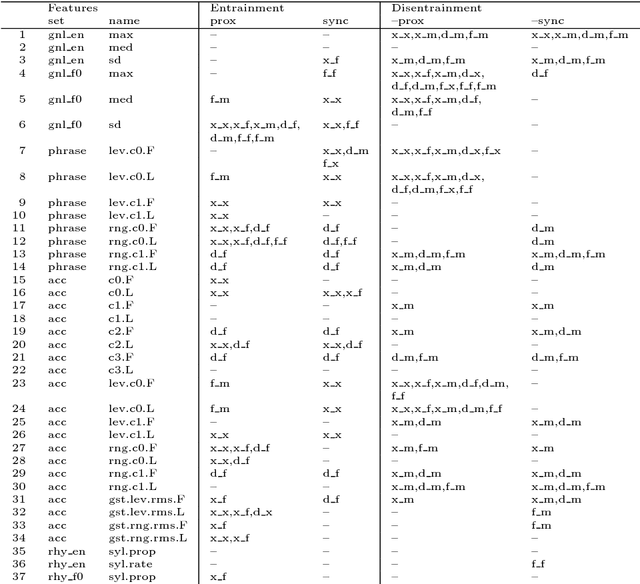
We examine prosodic entrainment in cooperative game dialogs for new feature sets describing register, pitch accent shape, and rhythmic aspects of utterances. For these as well as for established features we present entrainment profiles to detect within- and across-dialog entrainment by the speakers' gender and role in the game. It turned out, that feature sets undergo entrainment in different quantitative and qualitative ways, which can partly be attributed to their different functions. Furthermore, interactions between speaker gender and role (describer vs. follower) suggest gender-dependent strategies in cooperative solution-oriented interactions: female describers entrain most, male describers least. Our data suggests a slight advantage of the latter strategy on task success.
* Accepted Manuscript for Speech Communication (Elsevier), 25 April 2018
Contradiction Detection for Rumorous Claims
Nov 11, 2016



The utilization of social media material in journalistic workflows is increasing, demanding automated methods for the identification of mis- and disinformation. Since textual contradiction across social media posts can be a signal of rumorousness, we seek to model how claims in Twitter posts are being textually contradicted. We identify two different contexts in which contradiction emerges: its broader form can be observed across independently posted tweets and its more specific form in threaded conversations. We define how the two scenarios differ in terms of central elements of argumentation: claims and conversation structure. We design and evaluate models for the two scenarios uniformly as 3-way Recognizing Textual Entailment tasks in order to represent claims and conversation structure implicitly in a generic inference model, while previous studies used explicit or no representation of these properties. To address noisy text, our classifiers use simple similarity features derived from the string and part-of-speech level. Corpus statistics reveal distribution differences for these features in contradictory as opposed to non-contradictory tweet relations, and the classifiers yield state of the art performance.
* To appear in: Proceedings of Extra-Propositional Aspects of Meaning (ExProM) in Computational Linguistics, Osaka, Japan, 2016
Veracity Computing from Lexical Cues and Perceived Certainty Trends
Nov 11, 2016



We present a data-driven method for determining the veracity of a set of rumorous claims on social media data. Tweets from different sources pertaining to a rumor are processed on three levels: first, factuality values are assigned to each tweet based on four textual cue categories relevant for our journalism use case; these amalgamate speaker support in terms of polarity and commitment in terms of certainty and speculation. Next, the proportions of these lexical cues are utilized as predictors for tweet certainty in a generalized linear regression model. Subsequently, lexical cue proportions, predicted certainty, as well as their time course characteristics are used to compute veracity for each rumor in terms of the identity of the rumor-resolving tweet and its binary resolution value judgment. The system operates without access to extralinguistic resources. Evaluated on the data portion for which hand-labeled examples were available, it achieves .74 F1-score on identifying rumor resolving tweets and .76 F1-score on predicting if a rumor is resolved as true or false.
* to appear in: Proc. 2nd Workshop on Noisy User-generated Text, Osaka, Japan, 2016