 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training
Paper and Code



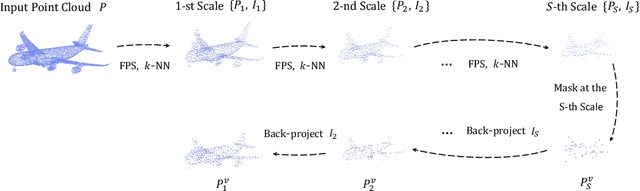
Masked Autoencoders (MAE) have shown great potentials in self-supervised pre-training for language and 2D image transformers. However, it still remains an open question on how to exploit masked autoencoding for learning 3D representations of irregular point clouds. In this paper, we propose Point-M2AE, a strong Multi-scale MAE pre-training framework for hierarchical self-supervised learning of 3D point clouds. Unlike the standard transformer in MAE, we modify the encoder and decoder into pyramid architectures to progressively model spatial geometries and capture both fine-grained and high-level semantics of 3D shapes. For the encoder that downsamples point tokens by stages, we design a multi-scale masking strategy to generate consistent visible regions across scales, and adopt a local spatial self-attention mechanism to focus on neighboring patterns. By multi-scale token propagation, the lightweight decoder gradually upsamples point tokens with complementary skip connections from the encoder, which further promotes the reconstruction from a global-to-local perspective. Extensive experiments demonstrate the state-of-the-art performance of Point-M2AE for 3D representation learning. With a frozen encoder after pre-training, Point-M2AE achieves 92.9% accuracy for linear SVM on ModelNet40, even surpassing some fully trained methods. By fine-tuning on downstream tasks, Point-M2AE achieves 86.43% accuracy on ScanObjectNN, +3.36% to the second-best, and largely benefits the few-shot classification, part segmentation and 3D object detection with the hierarchical pre-training scheme. Code will be available at https://github.com/ZrrSkywalker/Point-M2AE.