 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Red-Teaming Framework for Large Language Model Security Assessment: A Comprehensive Attack Generation and Detection System
Dec 21, 2025As large language models (LLMs) are increasingly deployed in high-stakes domains, ensuring their security and alignment has become a critical challenge. Existing red-teaming practices depend heavily on manual testing, which limits scalability and fails to comprehensively cover the vast space of potential adversarial behaviors. This paper introduces an automated red-teaming framework that systematically generates, executes, and evaluates adversarial prompts to uncover security vulnerabilities in LLMs. Our framework integrates meta-prompting-based attack synthesis, multi-modal vulnerability detection, and standardized evaluation protocols spanning six major threat categories -- reward hacking, deceptive alignment, data exfiltration, sandbagging, inappropriate tool use, and chain-of-thought manipulation. Experiments on the GPT-OSS-20B model reveal 47 distinct vulnerabilities, including 21 high-severity and 12 novel attack patterns, achieving a $3.9\times$ improvement in vulnerability discovery rate over manual expert testing while maintaining 89\% detection accuracy. These results demonstrate the framework's effectiveness in enabling scalable, systematic, and reproducible AI safety evaluations. By providing actionable insights for improving alignment robustness, this work advances the state of automated LLM red-teaming and contributes to the broader goal of building secure and trustworthy AI systems.
Shallow Features Matter: Hierarchical Memory with Heterogeneous Interaction for Unsupervised Video Object Segmentation
Jul 30, 2025

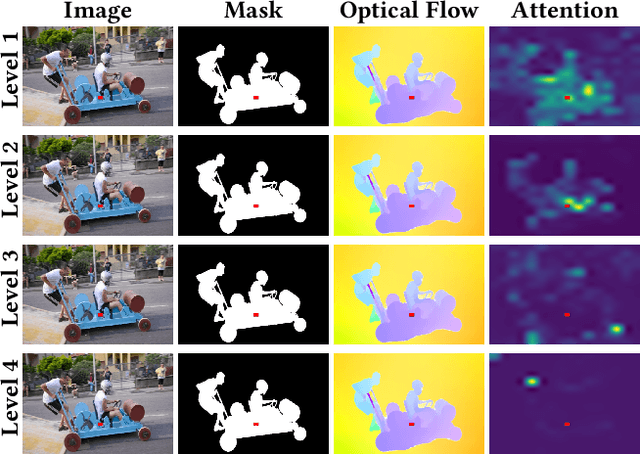
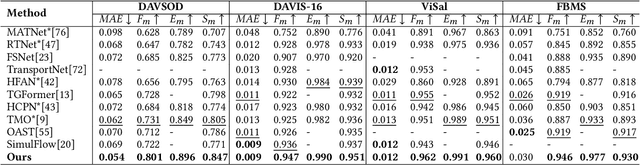
Unsupervised Video Object Segmentation (UVOS) aims to predict pixel-level masks for the most salient objects in videos without any prior annotations. While memory mechanisms have been proven critical in various video segmentation paradigms, their application in UVOS yield only marginal performance gains despite sophisticated design. Our analysis reveals a simple but fundamental flaw in existing methods: over-reliance on memorizing high-level semantic features. UVOS inherently suffers from the deficiency of lacking fine-grained information due to the absence of pixel-level prior knowledge. Consequently, memory design relying solely on high-level features, which predominantly capture abstract semantic cues, is insufficient to generate precise predictions. To resolve this fundamental issue, we propose a novel hierarchical memory architecture to incorporate both shallow- and high-level features for memory, which leverages the complementary benefits of pixel and semantic information. Furthermore, to balance the simultaneous utilization of the pixel and semantic memory features, we propose a heterogeneous interaction mechanism to perform pixel-semantic mutual interactions, which explicitly considers their inherent feature discrepancies. Through the design of Pixel-guided Local Alignment Module (PLAM) and Semantic-guided Global Integration Module (SGIM), we achieve delicate integration of the fine-grained details in shallow-level memory and the semantic representations in high-level memory. Our Hierarchical Memory with Heterogeneous Interaction Network (HMHI-Net) consistently achieves state-of-the-art performance across all UVOS and video saliency detection benchmarks. Moreover, HMHI-Net consistently exhibits high performance across different backbones, further demonstrating its superiority and robustness. Project page: https://github.com/ZhengxyFlow/HMHI-Net .
Analyzing Nobel Prize Literature with Large Language Models
Oct 22, 2024



This study examines the capabilities of advanced Large Language Models (LLMs), particularly the o1 model, in the context of literary analysis. The outputs of these models are compared directly to those produced by graduate-level human participants. By focusing on two Nobel Prize-winning short stories, 'Nine Chapters' by Han Kang, the 2024 laureate, and 'Friendship' by Jon Fosse, the 2023 laureate, the research explores the extent to which AI can engage with complex literary elements such as thematic analysis, intertextuality, cultural and historical contexts, linguistic and structural innovations, and character development. Given the Nobel Prize's prestige and its emphasis on cultural, historical, and linguistic richness, applying LLMs to these works provides a deeper understanding of both human and AI approaches to interpretation. The study uses qualitative and quantitative evaluations of coherence, creativity, and fidelity to the text, revealing the strengths and limitations of AI in tasks typically reserved for human expertise. While LLMs demonstrate strong analytical capabilities, particularly in structured tasks, they often fall short in emotional nuance and coherence, areas where human interpretation excels. This research underscores the potential for human-AI collaboration in the humanities, opening new opportunities in literary studies and beyond.
SIMRP: Self-Interference Mitigation Using RIS and Phase Shifter Network
Sep 13, 2024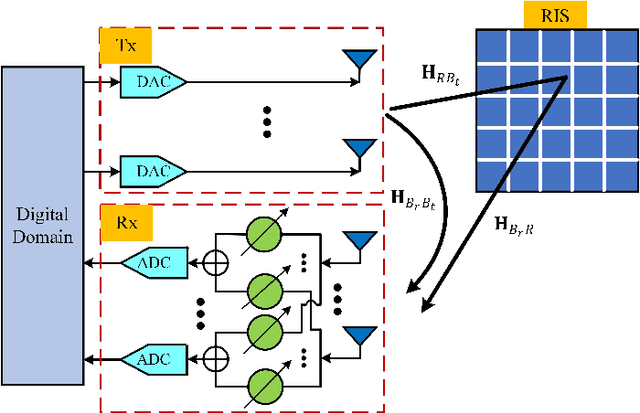
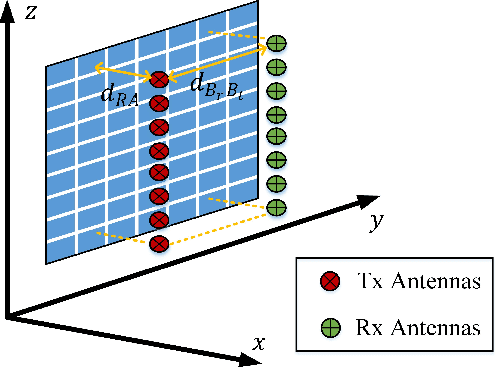


Strong self-interference due to the co-located transmitter is the bottleneck for implementing an in-band full-duplex (IBFD) system. If not adequately mitigated, the strong interference can saturate the receiver's analog-digital converters (ADCs) and hence void the digital processing. This paper considers utilizing a reconfigurable intelligent surface (RIS), together with a receiving (Rx) phase shifter network (PSN), to mitigate the strong self-interference through jointly optimizing their phases. This method, named self-interference mitigation using RIS and PSN (SIMRP), can suppress self-interference to avoid ADC saturation effectively and therefore improve the sum rate performance of communication systems, as verified by the simulation studies.
Practical Battery Health Monitoring using Uncertainty-Aware Bayesian Neural Network
Apr 20, 2024



Battery health monitoring and prediction are critically important in the era of electric mobility with a huge impact on safety, sustainability, and economic aspects. Existing research often focuses on prediction accuracy but tends to neglect practical factors that may hinder the technology's deployment in real-world applications. In this paper, we address these practical considerations and develop models based on the Bayesian neural network for predicting battery end-of-life. Our models use sensor data related to battery health and apply distributions, rather than single-point, for each parameter of the models. This allows the models to capture the inherent randomness and uncertainty of battery health, which leads to not only accurate predictions but also quantifiable uncertainty. We conducted an experimental study and demonstrated the effectiveness of our proposed models, with a prediction error rate averaging 13.9%, and as low as 2.9% for certain tested batteries. Additionally, all predictions include quantifiable certainty, which improved by 66% from the initial to the mid-life stage of the battery. This research has practical values for battery technologies and contributes to accelerating the technology adoption in the industry.
Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification
Jul 19, 2022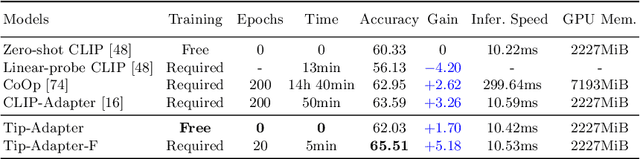
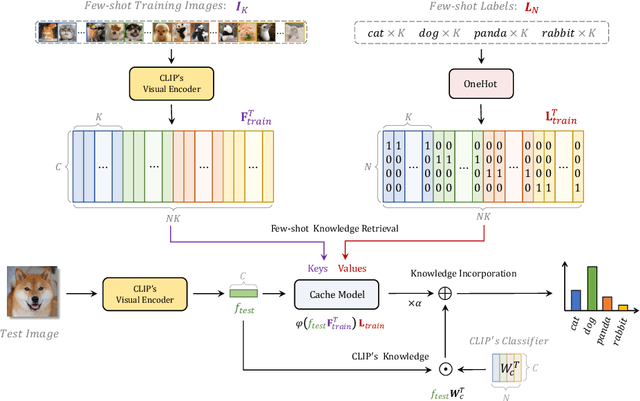
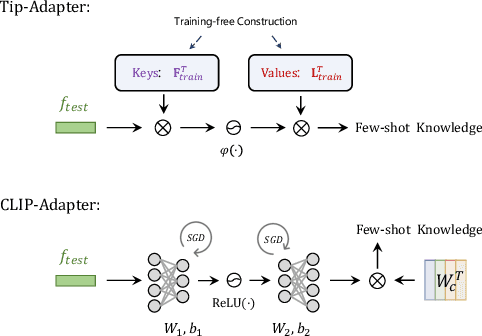

Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations using large-scale image-text pairs. It shows impressive performance on downstream tasks by zero-shot knowledge transfer. To further enhance CLIP's adaption capability, existing methods proposed to fine-tune additional learnable modules, which significantly improves the few-shot performance but introduces extra training time and computational resources. In this paper, we propose a training-free adaption method for CLIP to conduct few-shot classification, termed as Tip-Adapter, which not only inherits the training-free advantage of zero-shot CLIP but also performs comparably to those training-required approaches. Tip-Adapter constructs the adapter via a key-value cache model from the few-shot training set, and updates the prior knowledge encoded in CLIP by feature retrieval. On top of that, the performance of Tip-Adapter can be further boosted to be state-of-the-art on ImageNet by fine-tuning the cache model for 10$\times$ fewer epochs than existing methods, which is both effective and efficient. We conduct extensive experiments of few-shot classification on 11 datasets to demonstrate the superiority of our proposed methods. Code is released at https://github.com/gaopengcuhk/Tip-Adapter.
Can I use this publicly available dataset to build commercial AI software? Most likely not
Nov 09, 2021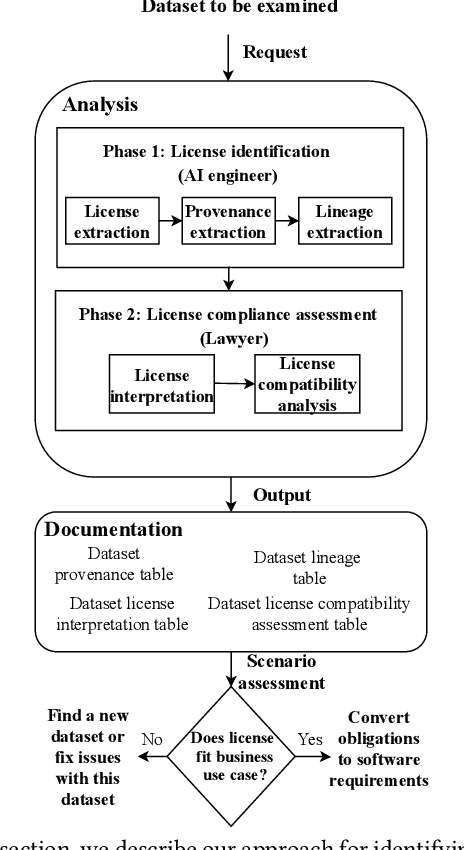

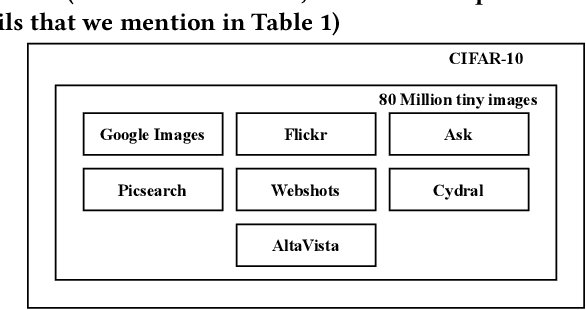
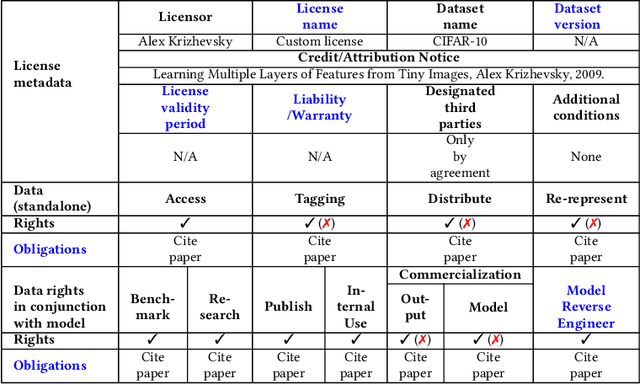
Publicly available datasets are one of the key drivers for commercial AI software. The use of publicly available datasets (particularly for commercial purposes) is governed by dataset licenses. These dataset licenses outline the rights one is entitled to on a given dataset and the obligations that one must fulfil to enjoy such rights without any license compliance violations. However, unlike standardized Open Source Software (OSS) licenses, existing dataset licenses are defined in an ad-hoc manner and do not clearly outline the rights and obligations associated with their usage. This makes checking for potential license compliance violations difficult. Further, a public dataset may be hosted in multiple locations and created from multiple data sources each of which may have different licenses. Hence, existing approaches on checking OSS license compliance cannot be used. In this paper, we propose a new approach to assess the potential license compliance violations if a given publicly available dataset were to be used for building commercial AI software. We conduct trials of our approach on two product groups within Huawei on 6 commonly used publicly available datasets. Our results show that there are risks of license violations on 5 of these 6 studied datasets if they were used for commercial purposes. Consequently, we provide recommendations for AI engineers on how to better assess publicly available datasets for license compliance violations.
CSI-based Outdoor Localization for Massive MIMO: Experiments with a Learning Approach
Jun 19, 2018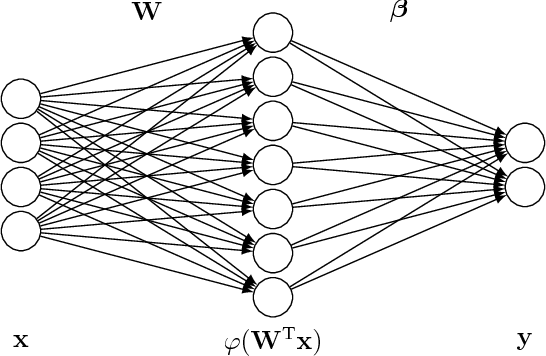
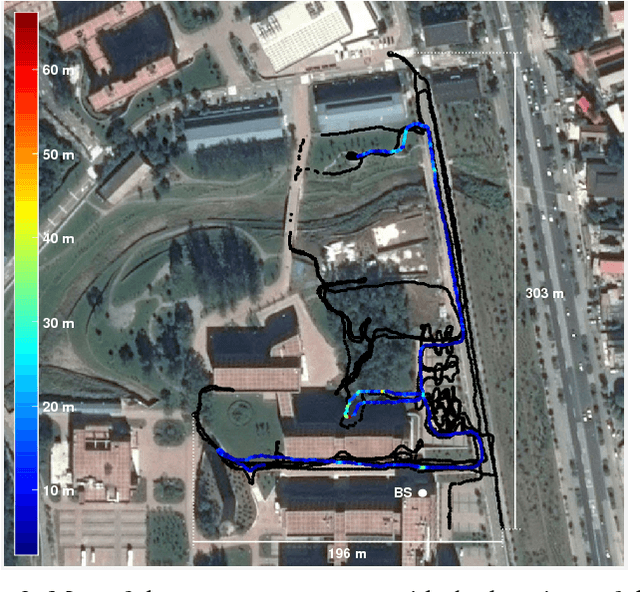

We report on experimental results on the use of a learning-based approach to infer the location of a mobile user of a cellular network within a cell, for a 5G-type Massive multiple input, multiple output (MIMO) system. We describe how the sample spatial covariance matrix computed from the CSI can be used as the input to a learning algorithm which attempts to relate it to user location. We discuss several learning approaches, and analyze in depth the application of extreme learning machines, for which theoretical approximate performance benchmarks are available, to the localization problem. We validate the proposed approach using experimental data collected on a Huawei 5G testbed, provide some performance and robustness benchmarks, and discuss practical issues related to the deployment of such a technique in 5G networks.