 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
Jun 09, 2023



3D multi-object tracking (MOT) is vital for many applications including autonomous driving vehicles and service robots. With the commonly used tracking-by-detection paradigm, 3D MOT has made important progress in recent years. However, these methods only use the detection boxes of the current frame to obtain trajectory-box association results, which makes it impossible for the tracker to recover objects missed by the detector. In this paper, we present TrajectoryFormer, a novel point-cloud-based 3D MOT framework. To recover the missed object by detector, we generates multiple trajectory hypotheses with hybrid candidate boxes, including temporally predicted boxes and current-frame detection boxes, for trajectory-box association. The predicted boxes can propagate object's history trajectory information to the current frame and thus the network can tolerate short-term miss detection of the tracked objects. We combine long-term object motion feature and short-term object appearance feature to create per-hypothesis feature embedding, which reduces the computational overhead for spatial-temporal encoding. Additionally, we introduce a Global-Local Interaction Module to conduct information interaction among all hypotheses and models their spatial relations, leading to accurate estimation of hypotheses. Our TrajectoryFormer achieves state-of-the-art performance on the Waymo 3D MOT benchmarks.
ConQueR: Query Contrast Voxel-DETR for 3D Object Detection
Dec 14, 2022



Although DETR-based 3D detectors can simplify the detection pipeline and achieve direct sparse predictions, their performance still lags behind dense detectors with post-processing for 3D object detection from point clouds. DETRs usually adopt a larger number of queries than GTs (e.g., 300 queries v.s. 40 objects in Waymo) in a scene, which inevitably incur many false positives during inference. In this paper, we propose a simple yet effective sparse 3D detector, named Query Contrast Voxel-DETR (ConQueR), to eliminate the challenging false positives, and achieve more accurate and sparser predictions. We observe that most false positives are highly overlapping in local regions, caused by the lack of explicit supervision to discriminate locally similar queries. We thus propose a Query Contrast mechanism to explicitly enhance queries towards their best-matched GTs over all unmatched query predictions. This is achieved by the construction of positive and negative GT-query pairs for each GT, and a contrastive loss to enhance positive GT-query pairs against negative ones based on feature similarities. ConQueR closes the gap of sparse and dense 3D detectors, and reduces up to ~60% false positives. Our single-frame ConQueR achieves new state-of-the-art (sota) 71.6 mAPH/L2 on the challenging Waymo Open Dataset validation set, outperforming previous sota methods (e.g., PV-RCNN++) by over 2.0 mAPH/L2.
MPPNet: Multi-Frame Feature Intertwining with Proxy Points for 3D Temporal Object Detection
May 12, 2022
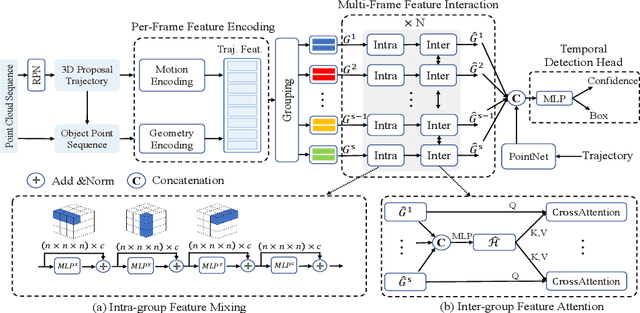
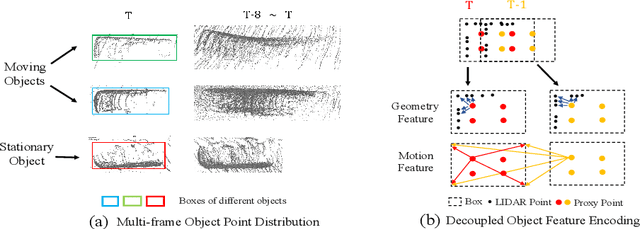
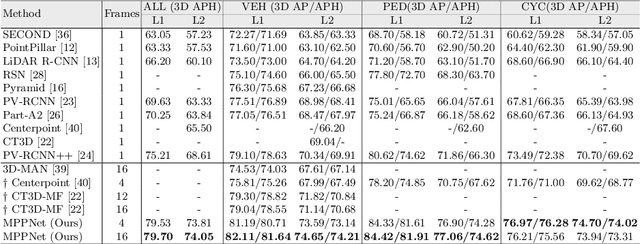
Accurate and reliable 3D detection is vital for many applications including autonomous driving vehicles and service robots. In this paper, we present a flexible and high-performance 3D detection framework, named MPPNet, for 3D temporal object detection with point cloud sequences. We propose a novel three-hierarchy framework with proxy points for multi-frame feature encoding and interactions to achieve better detection. The three hierarchies conduct per-frame feature encoding, short-clip feature fusion, and whole-sequence feature aggregation, respectively. To enable processing long-sequence point clouds with reasonable computational resources, intra-group feature mixing and inter-group feature attention are proposed to form the second and third feature encoding hierarchies, which are recurrently applied for aggregating multi-frame trajectory features. The proxy points not only act as consistent object representations for each frame, but also serve as the courier to facilitate feature interaction between frames. The experiments on largeWaymo Open dataset show that our approach outperforms state-of-the-art methods with large margins when applied to both short (e.g., 4-frame) and long (e.g., 16-frame) point cloud sequences. Specifically, MPPNet achieves 74.21%, 74.62% and 73.31% for vehicle, pedestrian and cyclist classes on the LEVEL 2 mAPH metric with 16-frame input.
EqCo: Equivalent Rules for Self-supervised Contrastive Learning
Oct 05, 2020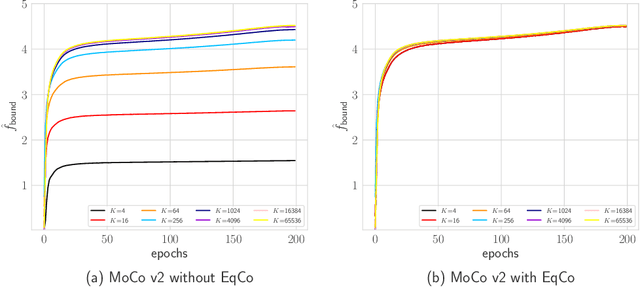


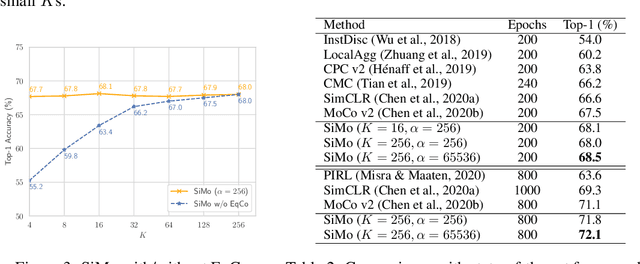
In this paper, we propose a method, named EqCo (Equivalent Rules for Contrastive Learning), to make self-supervised learning irrelevant to the number of negative samples in the contrastive learning framework. Inspired by the infomax principle, we point that the margin term in contrastive loss needs to be adaptively scaled according to the number of negative pairs in order to keep steady mutual information bound and gradient magnitude. EqCo bridges the performance gap among a wide range of negative sample sizes, so that for the first time, we can perform self-supervised contrastive training using only a few negative pairs (e.g.smaller than 256 per query) on large-scale vision tasks like ImageNet, while with little accuracy drop. This is quite a contrast to the widely used large batch training or memory bank mechanism in current practices. Equipped with EqCo, our simplified MoCo (SiMo) achieves comparable accuracy with MoCo v2 on ImageNet (linear evaluation protocol) while only involves 16 negative pairs per query instead of 65536, suggesting that large quantities of negative samples might not be a critical factor in contrastive learning frameworks.
AutoAssign: Differentiable Label Assignment for Dense Object Detection
Jul 07, 2020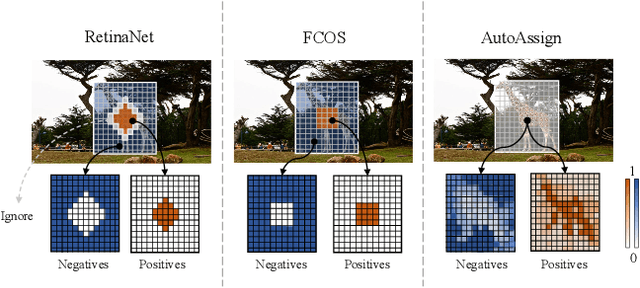
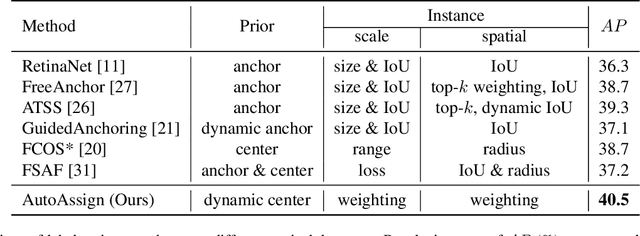

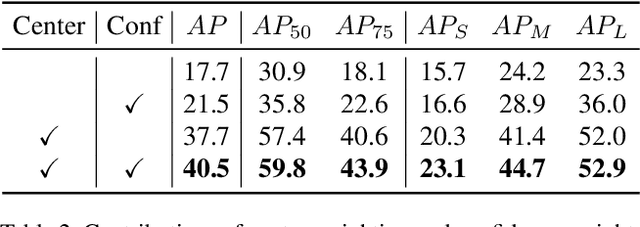
In this paper, we propose an anchor-free object detector with a fully differentiable label assignment strategy, named AutoAssign. It automatically determines positive/negative samples by generating positive and negative weight maps to modify each location's prediction dynamically. Specifically, we present a center weighting module to adjust the category-specific prior distributions and a confidence weighting module to adapt the specific assign strategy of each instance. The entire label assignment process is differentiable and requires no additional modification to transfer to different datasets and tasks. Extensive experiments on MS COCO show that our method steadily surpasses other best sampling strategies by $ \sim $ 1\% AP with various backbones. Moreover, our best model achieves 52.1\% AP, outperforming all existing one-stage detectors. Besides, experiments on other datasets, \emph{e.g.}, PASCAL VOC, Objects365, and WiderFace, demonstrate the broad applicability of AutoAssign.
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
Aug 26, 2019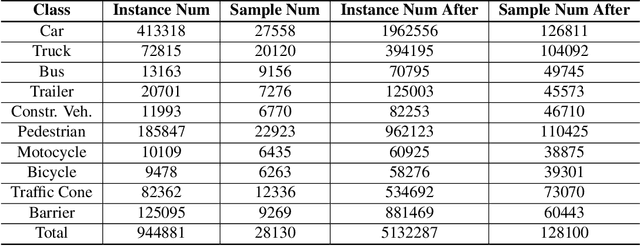

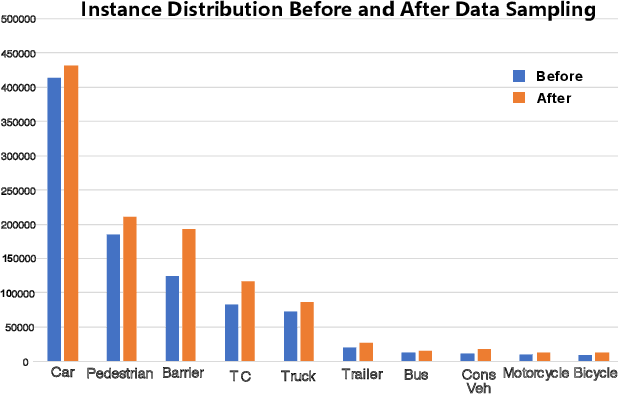

This report presents our method which wins the nuScenes3D Detection Challenge [17] held in Workshop on Autonomous Driving(WAD, CVPR 2019). Generally, we utilize sparse 3D convolution to extract rich semantic features, which are then fed into a class-balanced multi-head network to perform 3D object detection. To handle the severe class imbalance problem inherent in the autonomous driving scenarios, we design a class-balanced sampling and augmentation strategy to generate a more balanced data distribution. Furthermore, we propose a balanced group-ing head to boost the performance for the categories withsimilar shapes. Based on the Challenge results, our methodoutperforms the PointPillars [14] baseline by a large mar-gin across all metrics, achieving state-of-the-art detection performance on the nuScenes dataset. Code will be released at CBGS.