 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEEL: Multi-Modal Event Evolution Learning
Apr 16, 2024



Multi-modal Event Reasoning (MMER) endeavors to endow machines with the ability to comprehend intricate event relations across diverse data modalities. MMER is fundamental and underlies a wide broad of applications. Despite extensive instruction fine-tuning, current multi-modal large language models still fall short in such ability. The disparity stems from that existing models are insufficient to capture underlying principles governing event evolution in various scenarios. In this paper, we introduce Multi-Modal Event Evolution Learning (MEEL) to enable the model to grasp the event evolution mechanism, yielding advanced MMER ability. Specifically, we commence with the design of event diversification to gather seed events from a rich spectrum of scenarios. Subsequently, we employ ChatGPT to generate evolving graphs for these seed events. We propose an instruction encapsulation process that formulates the evolving graphs into instruction-tuning data, aligning the comprehension of event reasoning to humans. Finally, we observe that models trained in this way are still struggling to fully comprehend event evolution. In such a case, we propose the guiding discrimination strategy, in which models are trained to discriminate the improper evolution direction. We collect and curate a benchmark M-EV2 for MMER. Extensive experiments on M-EV2 validate the effectiveness of our approach, showcasing competitive performance in open-source multi-modal LLMs.
Steal My Artworks for Fine-tuning? A Watermarking Framework for Detecting Art Theft Mimicry in Text-to-Image Models
Nov 22, 2023The advancement in text-to-image models has led to astonishing artistic performances. However, several studios and websites illegally fine-tune these models using artists' artworks to mimic their styles for profit, which violates the copyrights of artists and diminishes their motivation to produce original works. Currently, there is a notable lack of research focusing on this issue. In this paper, we propose a novel watermarking framework that detects mimicry in text-to-image models through fine-tuning. This framework embeds subtle watermarks into digital artworks to protect their copyrights while still preserving the artist's visual expression. If someone takes watermarked artworks as training data to mimic an artist's style, these watermarks can serve as detectable indicators. By analyzing the distribution of these watermarks in a series of generated images, acts of fine-tuning mimicry using stolen victim data will be exposed. In various fine-tune scenarios and against watermark attack methods, our research confirms that analyzing the distribution of watermarks in artificially generated images reliably detects unauthorized mimicry.
Pixel-Wise Contrastive Distillation
Nov 01, 2022We present the first pixel-level self-supervised distillation framework specified for dense prediction tasks. Our approach, called Pixel-Wise Contrastive Distillation (PCD), distills knowledge by attracting the corresponding pixels from student's and teacher's output feature maps. This pixel-to-pixel distillation demands for maintaining the spatial information of teacher's output. We propose a SpatialAdaptor that adapts the well-trained projection/prediction head of the teacher used to encode vectorized features to processing 2D feature maps. SpatialAdaptor enables more informative pixel-level distillation, yielding a better student for dense prediction tasks. Besides, in light of the inadequate effective receptive fields of small models, we utilize a plug-in multi-head self-attention module to explicitly relate the pixels of student's feature maps. Overall, our PCD outperforms previous self-supervised distillation methods on various dense prediction tasks. A backbone of ResNet-18 distilled by PCD achieves $37.4$ AP$^\text{bbox}$ and $34.0$ AP$^{mask}$ with Mask R-CNN detector on COCO dataset, emerging as the first pre-training method surpassing the supervised pre-trained counterpart.
Revisiting the Critical Factors of Augmentation-Invariant Representation Learning
Jul 30, 2022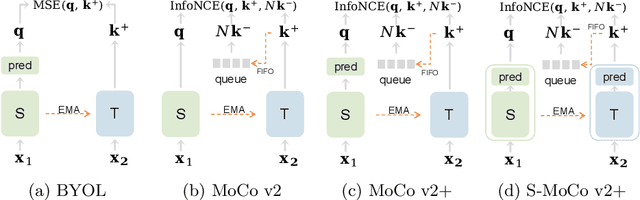

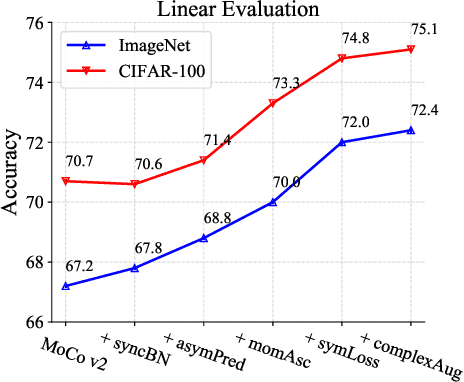
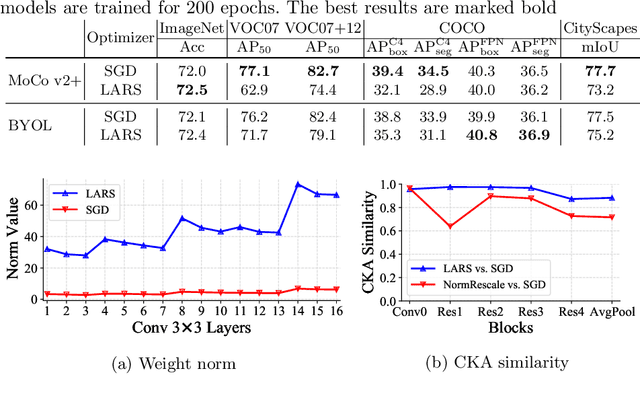
We focus on better understanding the critical factors of augmentation-invariant representation learning. We revisit MoCo v2 and BYOL and try to prove the authenticity of the following assumption: different frameworks bring about representations of different characteristics even with the same pretext task. We establish the first benchmark for fair comparisons between MoCo v2 and BYOL, and observe: (i) sophisticated model configurations enable better adaptation to pre-training dataset; (ii) mismatched optimization strategies of pre-training and fine-tuning hinder model from achieving competitive transfer performances. Given the fair benchmark, we make further investigation and find asymmetry of network structure endows contrastive frameworks to work well under the linear evaluation protocol, while may hurt the transfer performances on long-tailed classification tasks. Moreover, negative samples do not make models more sensible to the choice of data augmentations, nor does the asymmetric network structure. We believe our findings provide useful information for future work.
EqCo: Equivalent Rules for Self-supervised Contrastive Learning
Oct 05, 2020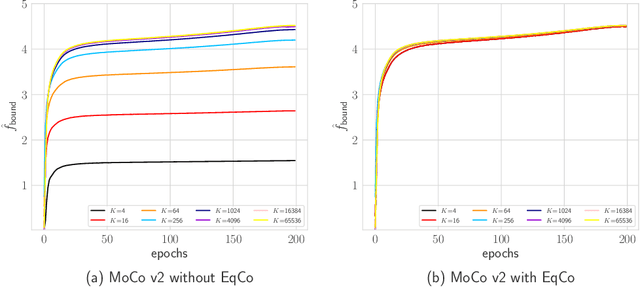


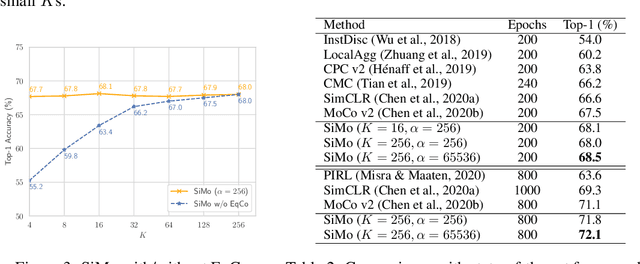
In this paper, we propose a method, named EqCo (Equivalent Rules for Contrastive Learning), to make self-supervised learning irrelevant to the number of negative samples in the contrastive learning framework. Inspired by the infomax principle, we point that the margin term in contrastive loss needs to be adaptively scaled according to the number of negative pairs in order to keep steady mutual information bound and gradient magnitude. EqCo bridges the performance gap among a wide range of negative sample sizes, so that for the first time, we can perform self-supervised contrastive training using only a few negative pairs (e.g.smaller than 256 per query) on large-scale vision tasks like ImageNet, while with little accuracy drop. This is quite a contrast to the widely used large batch training or memory bank mechanism in current practices. Equipped with EqCo, our simplified MoCo (SiMo) achieves comparable accuracy with MoCo v2 on ImageNet (linear evaluation protocol) while only involves 16 negative pairs per query instead of 65536, suggesting that large quantities of negative samples might not be a critical factor in contrastive learning frameworks.