 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of YOLOv8 to YOLOv11 Performance in Underwater Vision Tasks
Sep 16, 2025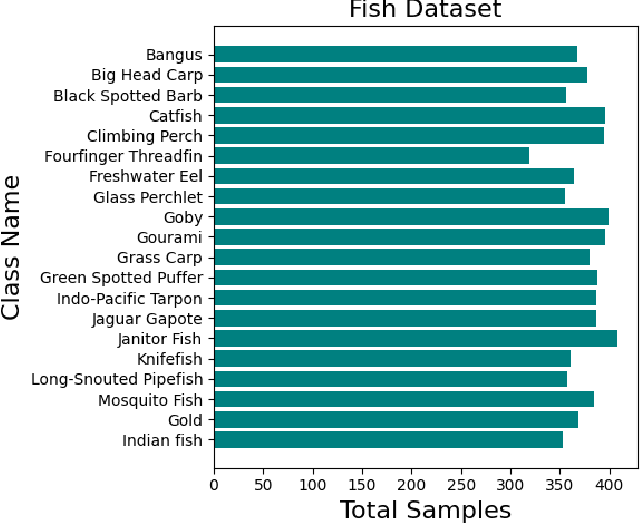
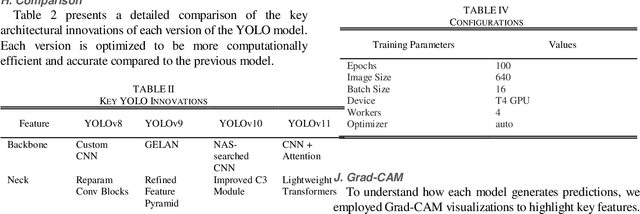
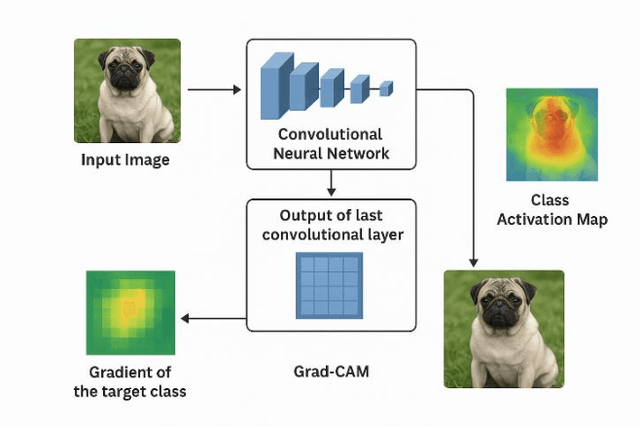
Autonomous underwater vehicles (AUVs) increasingly rely on on-board computer-vision systems for tasks such as habitat mapping, ecological monitoring, and infrastructure inspection. However, underwater imagery is hindered by light attenuation, turbidity, and severe class imbalance, while the computational resources available on AUVs are limited. One-stage detectors from the YOLO family are attractive because they fuse localization and classification in a single, low-latency network; however, their terrestrial benchmarks (COCO, PASCAL-VOC, Open Images) leave open the question of how successive YOLO releases perform in the marine domain. We curate two openly available datasets that span contrasting operating conditions: a Coral Disease set (4,480 images, 18 classes) and a Fish Species set (7,500 images, 20 classes). For each dataset, we create four training regimes (25 %, 50 %, 75 %, 100 % of the images) while keeping balanced validation and test partitions fixed. We train YOLOv8-s, YOLOv9-s, YOLOv10-s, and YOLOv11-s with identical hyperparameters (100 epochs, 640 px input, batch = 16, T4 GPU) and evaluate precision, recall, mAP50, mAP50-95, per-image inference time, and frames-per-second (FPS). Post-hoc Grad-CAM visualizations probe feature utilization and localization faithfulness. Across both datasets, accuracy saturates after YOLOv9, suggesting architectural innovations primarily target efficiency rather than accuracy. Inference speed, however, improves markedly. Our results (i) provide the first controlled comparison of recent YOLO variants on underwater imagery, (ii) show that lightweight YOLOv10 offers the best speed-accuracy trade-off for embedded AUV deployment, and (iii) deliver an open, reproducible benchmark and codebase to accelerate future marine-vision research.
RTify: Aligning Deep Neural Networks with Human Behavioral Decisions
Nov 06, 2024



Current neural network models of primate vision focus on replicating overall levels of behavioral accuracy, often neglecting perceptual decisions' rich, dynamic nature. Here, we introduce a novel computational framework to model the dynamics of human behavioral choices by learning to align the temporal dynamics of a recurrent neural network (RNN) to human reaction times (RTs). We describe an approximation that allows us to constrain the number of time steps an RNN takes to solve a task with human RTs. The approach is extensively evaluated against various psychophysics experiments. We also show that the approximation can be used to optimize an "ideal-observer" RNN model to achieve an optimal tradeoff between speed and accuracy without human data. The resulting model is found to account well for human RT data. Finally, we use the approximation to train a deep learning implementation of the popular Wong-Wang decision-making model. The model is integrated with a convolutional neural network (CNN) model of visual processing and evaluated using both artificial and natural image stimuli. Overall, we present a novel framework that helps align current vision models with human behavior, bringing us closer to an integrated model of human vision.