 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Negative Sampling for Contrastive Learning of Visual Representations
Oct 05, 2020


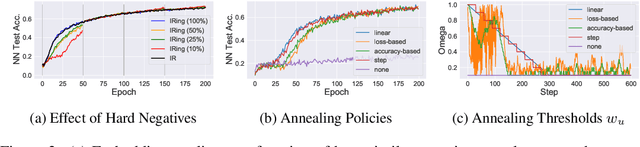
Recent methods for learning unsupervised visual representations, dubbed contrastive learning, optimize the noise-contrastive estimation (NCE) bound on mutual information between two views of an image. NCE uses randomly sampled negative examples to normalize the objective. In this paper, we show that choosing difficult negatives, or those more similar to the current instance, can yield stronger representations. To do this, we introduce a family of mutual information estimators that sample negatives conditionally -- in a "ring" around each positive. We prove that these estimators lower-bound mutual information, with higher bias but lower variance than NCE. Experimentally, we find our approach, applied on top of existing models (IR, CMC, and MoCo) improves accuracy by 2-5% points in each case, measured by linear evaluation on four standard image datasets. Moreover, we find continued benefits when transferring features to a variety of new image distributions from the Meta-Dataset collection and to a variety of downstream tasks such as object detection, instance segmentation, and keypoint detection.
On Mutual Information in Contrastive Learning for Visual Representations
Jun 05, 2020
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image where typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of negative samples and views are critical to the success of these algorithms. Reformulating previous learning objectives in terms of mutual information also simplifies and stabilizes them. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. % experiments show that choosing more difficult negative samples results in a stronger representation, outperforming those learned with IR, LA, and CMC in classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Zero Shot Learning for Code Education: Rubric Sampling with Deep Learning Inference
Sep 05, 2018


In modern computer science education, massive open online courses (MOOCs) log thousands of hours of data about how students solve coding challenges. Being so rich in data, these platforms have garnered the interest of the machine learning community, with many new algorithms attempting to autonomously provide feedback to help future students learn. But what about those first hundred thousand students? In most educational contexts (i.e. classrooms), assignments do not have enough historical data for supervised learning. In this paper, we introduce a human-in-the-loop "rubric sampling" approach to tackle the "zero shot" feedback challenge. We are able to provide autonomous feedback for the first students working on an introductory programming assignment with accuracy that substantially outperforms data-hungry algorithms and approaches human level fidelity. Rubric sampling requires minimal teacher effort, can associate feedback with specific parts of a student's solution and can articulate a student's misconceptions in the language of the instructor. Deep learning inference enables rubric sampling to further improve as more assignment specific student data is acquired. We demonstrate our results on a novel dataset from Code.org, the world's largest programming education platform.