 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Free Recognition with Transformers
Jan 05, 2026Transformers excel on tasks that process well-formed inputs according to some grammar, such as natural language and code. However, it remains unclear how they can process grammatical syntax. In fact, under standard complexity conjectures, standard transformers cannot recognize context-free languages (CFLs), a canonical formalism to describe syntax, or even regular languages, a subclass of CFLs (Merrill et al., 2022). Merrill & Sabharwal (2024) show that $\mathcal{O}(\log n)$ looping layers (w.r.t. input length $n$) allows transformers to recognize regular languages, but the question of context-free recognition remained open. In this work, we show that looped transformers with $\mathcal{O}(\log n)$ looping layers and $\mathcal{O}(n^6)$ padding tokens can recognize all CFLs. However, training and inference with $\mathcal{O}(n^6)$ padding tokens is potentially impractical. Fortunately, we show that, for natural subclasses such as unambiguous CFLs, the recognition problem on transformers becomes more tractable, requiring $\mathcal{O}(n^3)$ padding. We empirically validate our results and show that looping helps on a language that provably requires logarithmic depth. Overall, our results shed light on the intricacy of CFL recognition by transformers: While general recognition may require an intractable amount of padding, natural constraints such as unambiguity yield efficient recognition algorithms.
Generative Linguistics, Large Language Models, and the Social Nature of Scientific Success
Mar 25, 2025Chesi's (forthcoming) target paper depicts a generative linguistics in crisis, foreboded by Piantadosi's (2023) declaration that "modern language models refute Chomsky's approach to language." In order to survive, Chesi warns, generativists must hold themselves to higher standards of formal and empirical rigor. This response argues that the crisis described by Chesi and Piantadosi actually has little to do with rigor, but is rather a reflection of generativists' limited social ambitions. Chesi ties the fate of generative linguistics to its intellectual merits, but the current success of language model research is social in nature as much as it is intellectual. In order to thrive, then, generativists must do more than heed Chesi's call for rigor; they must also expand their ambitions by giving outsiders a stake in their future success.
What Goes Into a LM Acceptability Judgment? Rethinking the Impact of Frequency and Length
Nov 04, 2024


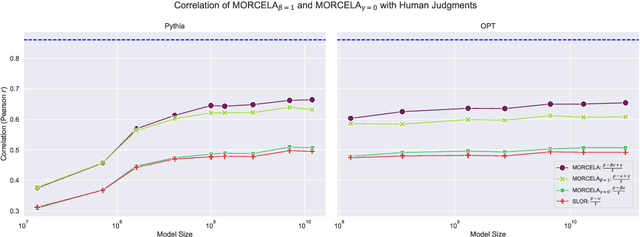
When comparing the linguistic capabilities of language models (LMs) with humans using LM probabilities, factors such as the length of the sequence and the unigram frequency of lexical items have a significant effect on LM probabilities in ways that humans are largely robust to. Prior works in comparing LM and human acceptability judgments treat these effects uniformly across models, making a strong assumption that models require the same degree of adjustment to control for length and unigram frequency effects. We propose MORCELA, a new linking theory between LM scores and acceptability judgments where the optimal level of adjustment for these effects is estimated from data via learned parameters for length and unigram frequency. We first show that MORCELA outperforms a commonly used linking theory for acceptability--SLOR (Pauls and Klein, 2012; Lau et al. 2017)--across two families of transformer LMs (Pythia and OPT). Furthermore, we demonstrate that the assumed degrees of adjustment in SLOR for length and unigram frequency overcorrect for these confounds, and that larger models require a lower relative degree of adjustment for unigram frequency, though a significant amount of adjustment is still necessary for all models. Finally, our subsequent analysis shows that larger LMs' lower susceptibility to frequency effects can be explained by an ability to better predict rarer words in context.
ERAS: Evaluating the Robustness of Chinese NLP Models to Morphological Garden Path Errors
Oct 16, 2024



In languages without orthographic word boundaries, NLP models perform word segmentation, either as an explicit preprocessing step or as an implicit step in an end-to-end computation. This paper shows that Chinese NLP models are vulnerable to morphological garden path errors: errors caused by a failure to resolve local word segmentation ambiguities using sentence-level morphosyntactic context. We propose a benchmark, ERAS, that tests a model's vulnerability to morphological garden path errors by comparing its behavior on sentences with and without local segmentation ambiguities. Using ERAS, we show that word segmentation models make garden path errors on locally ambiguous sentences, but do not make equivalent errors on unambiguous sentences. We further show that sentiment analysis models with character-level tokenization make implicit garden path errors, even without an explicit word segmentation step in the pipeline. Our results indicate that models' segmentation of Chinese text often fails to account for morphosyntactic context.
Reflecting the Male Gaze: Quantifying Female Objectification in 19th and 20th Century Novels
Mar 25, 2024Inspired by the concept of the male gaze (Mulvey, 1975) in literature and media studies, this paper proposes a framework for analyzing gender bias in terms of female objectification: the extent to which a text portrays female individuals as objects of visual pleasure. Our framework measures female objectification along two axes. First, we compute an agency bias score that indicates whether male entities are more likely to appear in the text as grammatical agents than female entities. Next, by analyzing the word embedding space induced by a text (Caliskan et al., 2017), we compute an appearance bias score that indicates whether female entities are more closely associated with appearance-related words than male entities. Applying our framework to 19th and 20th century novels reveals evidence of female objectification in literature: we find that novels written from a male perspective systematically objectify female characters, while novels written from a female perspective do not exhibit statistically significant objectification of any gender.
Verb Conjugation in Transformers Is Determined by Linear Encodings of Subject Number
Oct 23, 2023Deep architectures such as Transformers are sometimes criticized for having uninterpretable "black-box" representations. We use causal intervention analysis to show that, in fact, some linguistic features are represented in a linear, interpretable format. Specifically, we show that BERT's ability to conjugate verbs relies on a linear encoding of subject number that can be manipulated with predictable effects on conjugation accuracy. This encoding is found in the subject position at the first layer and the verb position at the last layer, but distributed across positions at middle layers, particularly when there are multiple cues to subject number.