 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Domain Adaptation for Low Light RAW Image Enhancement
Mar 27, 2023



Enhancing practical low light raw images is a difficult task due to severe noise and color distortions from short exposure time and limited illumination. Despite the success of existing Convolutional Neural Network (CNN) based methods, their performance is not adaptable to different camera domains. In addition, such methods also require large datasets with short-exposure and corresponding long-exposure ground truth raw images for each camera domain, which is tedious to compile. To address this issue, we present a novel few-shot domain adaptation method to utilize the existing source camera labeled data with few labeled samples from the target camera to improve the target domain's enhancement quality in extreme low-light imaging. Our experiments show that only ten or fewer labeled samples from the target camera domain are sufficient to achieve similar or better enhancement performance than training a model with a large labeled target camera dataset. To support research in this direction, we also present a new low-light raw image dataset captured with a Nikon camera, comprising short-exposure and their corresponding long-exposure ground truth images.
* BMVC 2021 Best Student Paper Award (Runner-Up). Project Page: https://val.cds.iisc.ac.in/HDR/BMVC21/index.html
Segmentation Guided Deep HDR Deghosting
Jul 04, 2022


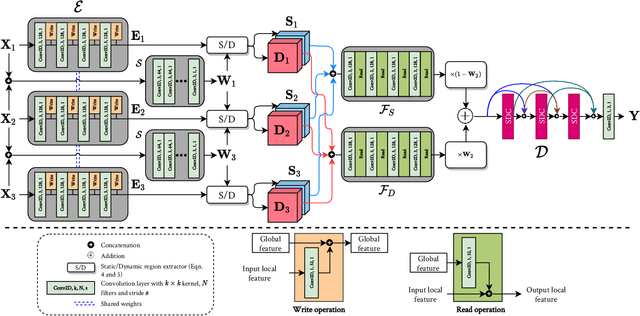
We present a motion segmentation guided convolutional neural network (CNN) approach for high dynamic range (HDR) image deghosting. First, we segment the moving regions in the input sequence using a CNN. Then, we merge static and moving regions separately with different fusion networks and combine fused features to generate the final ghost-free HDR image. Our motion segmentation guided HDR fusion approach offers significant advantages over existing HDR deghosting methods. First, by segmenting the input sequence into static and moving regions, our proposed approach learns effective fusion rules for various challenging saturation and motion types. Second, we introduce a novel memory network that accumulates the necessary features required to generate plausible details in the saturated regions. The proposed method outperforms nine existing state-of-the-art methods on two publicly available datasets and generates visually pleasing ghost-free HDR results. We also present a large-scale motion segmentation dataset of 3683 varying exposure images to benefit the research community.
Self-Gated Memory Recurrent Network for Efficient Scalable HDR Deghosting
Dec 24, 2021

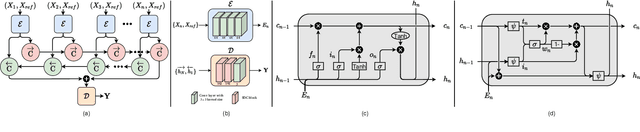

We propose a novel recurrent network-based HDR deghosting method for fusing arbitrary length dynamic sequences. The proposed method uses convolutional and recurrent architectures to generate visually pleasing, ghosting-free HDR images. We introduce a new recurrent cell architecture, namely Self-Gated Memory (SGM) cell, that outperforms the standard LSTM cell while containing fewer parameters and having faster running times. In the SGM cell, the information flow through a gate is controlled by multiplying the gate's output by a function of itself. Additionally, we use two SGM cells in a bidirectional setting to improve output quality. The proposed approach achieves state-of-the-art performance compared to existing HDR deghosting methods quantitatively across three publicly available datasets while simultaneously achieving scalability to fuse variable-length input sequence without necessitating re-training. Through extensive ablations, we demonstrate the importance of individual components in our proposed approach. The code is available at https://val.cds.iisc.ac.in/HDR/HDRRNN/index.html.
* 12 pages
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
Dec 20, 2017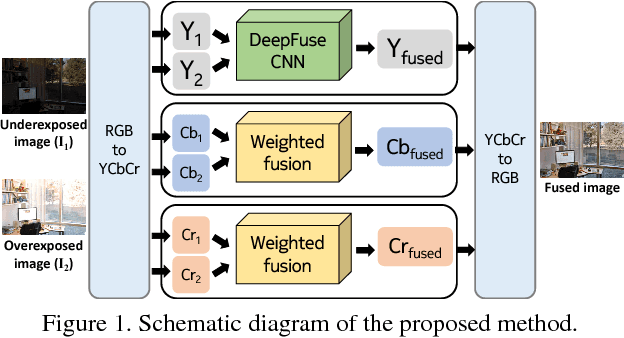
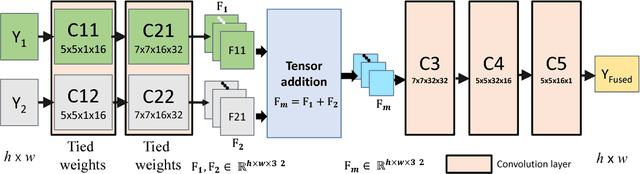
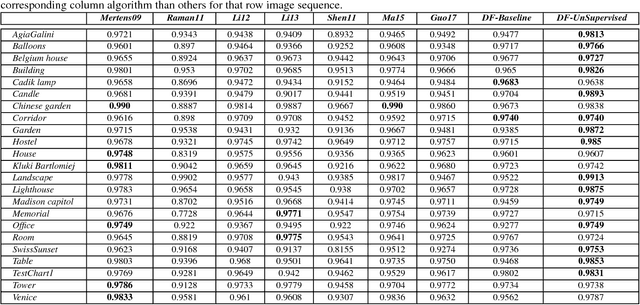
We present a novel deep learning architecture for fusing static multi-exposure images. Current multi-exposure fusion (MEF) approaches use hand-crafted features to fuse input sequence. However, the weak hand-crafted representations are not robust to varying input conditions. Moreover, they perform poorly for extreme exposure image pairs. Thus, it is highly desirable to have a method that is robust to varying input conditions and capable of handling extreme exposure without artifacts. Deep representations have known to be robust to input conditions and have shown phenomenal performance in a supervised setting. However, the stumbling block in using deep learning for MEF was the lack of sufficient training data and an oracle to provide the ground-truth for supervision. To address the above issues, we have gathered a large dataset of multi-exposure image stacks for training and to circumvent the need for ground truth images, we propose an unsupervised deep learning framework for MEF utilizing a no-reference quality metric as loss function. The proposed approach uses a novel CNN architecture trained to learn the fusion operation without reference ground truth image. The model fuses a set of common low level features extracted from each image to generate artifact-free perceptually pleasing results. We perform extensive quantitative and qualitative evaluation and show that the proposed technique outperforms existing state-of-the-art approaches for a variety of natural images.