 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End Bangla Speech Synthesis
Aug 01, 2021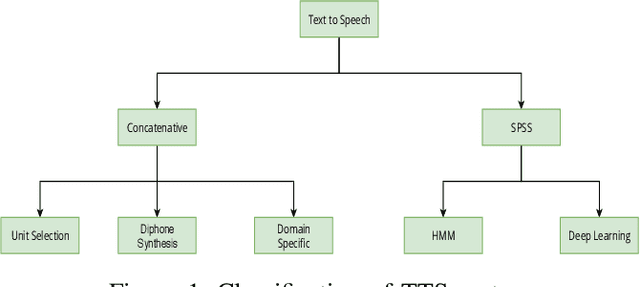
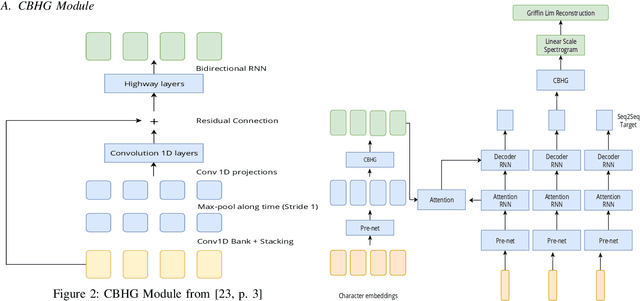
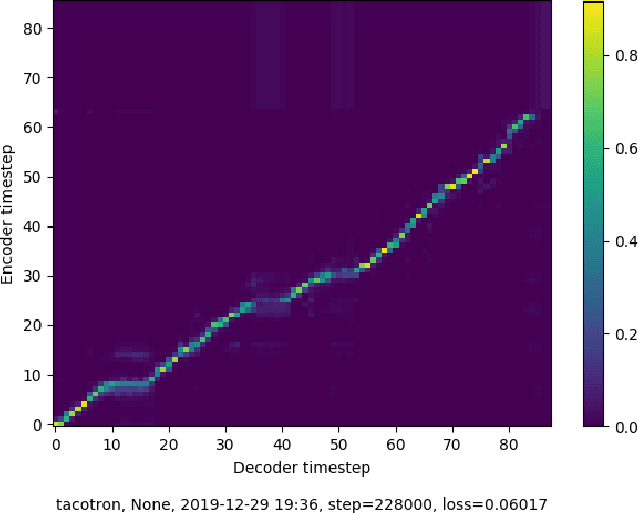
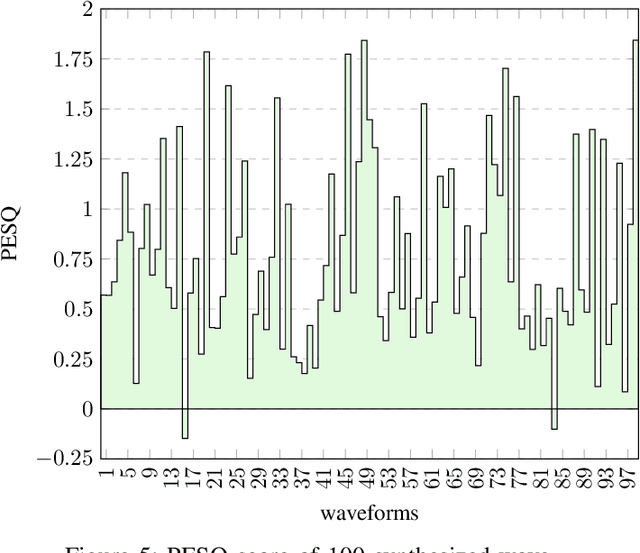
Text-to-Speech (TTS) system is a system where speech is synthesized from a given text following any particular approach. Concatenative synthesis, Hidden Markov Model (HMM) based synthesis, Deep Learning (DL) based synthesis with multiple building blocks, etc. are the main approaches for implementing a TTS system. Here, we are presenting our deep learning-based end-to-end Bangla speech synthesis system. It has been implemented with minimal human annotation using only 3 major components (Encoder, Decoder, Post-processing net including waveform synthesis). It does not require any frontend preprocessor and Grapheme-to-Phoneme (G2P) converter. Our model has been trained with phonetically balanced 20 hours of single speaker speech data. It has obtained a 3.79 Mean Opinion Score (MOS) on a scale of 5.0 as subjective evaluation and a 0.77 Perceptual Evaluation of Speech Quality(PESQ) score on a scale of [-0.5, 4.5] as objective evaluation. It is outperforming all existing non-commercial state-of-the-art Bangla TTS systems based on naturalness.