 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the effect of domain selection on automatic speech recognition performance: a case study on Bangladeshi Bangla
Oct 24, 2022The performance of data-driven natural language processing systems is contingent upon the quality of corpora. However, principal corpus design criteria are often not identified and examined adequately, particularly in the speech processing discipline. Speech corpora development requires additional attention with regard to clean/noisy, read/spontaneous, multi-talker speech, accents/dialects, etc. Domain selection is also a crucial decision point in speech corpus development. In this study, we demonstrate the significance of domain selection by assessing a state-of-the-art Bangla automatic speech recognition (ASR) model on a novel multi-domain Bangladeshi Bangla ASR evaluation benchmark - BanSpeech, which contains 7.2 hours of speech and 9802 utterances from 19 distinct domains. The ASR model has been trained with deep convolutional neural network (CNN), layer normalization technique, and Connectionist Temporal Classification (CTC) loss criterion on SUBAK.KO, a mostly read speech corpus for the low-resource and morphologically rich language Bangla. Experimental evaluation reveals the ASR model on SUBAK.KO faces difficulty recognizing speech from domains with mostly spontaneous speech and has a high number of out-of-vocabulary (OOV) words. The same ASR model, on the other hand, performs better in read speech domains and contains fewer OOV words. In addition, we report the outcomes of our experiments with layer normalization, input feature extraction, number of convolutional layers, etc., and set a baseline on SUBAK.KO. The BanSpeech will be publicly available to meet the need for a challenging evaluation benchmark for Bangla ASR.
End to End Bangla Speech Synthesis
Aug 01, 2021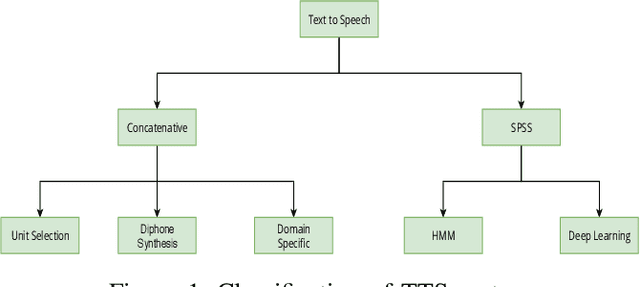
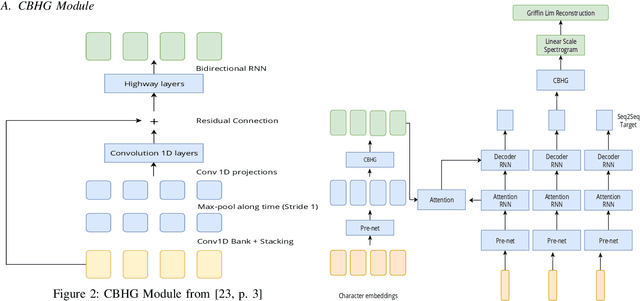
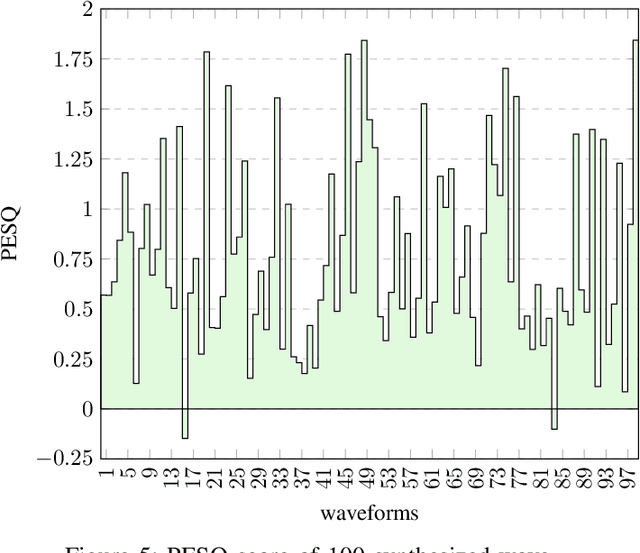
Text-to-Speech (TTS) system is a system where speech is synthesized from a given text following any particular approach. Concatenative synthesis, Hidden Markov Model (HMM) based synthesis, Deep Learning (DL) based synthesis with multiple building blocks, etc. are the main approaches for implementing a TTS system. Here, we are presenting our deep learning-based end-to-end Bangla speech synthesis system. It has been implemented with minimal human annotation using only 3 major components (Encoder, Decoder, Post-processing net including waveform synthesis). It does not require any frontend preprocessor and Grapheme-to-Phoneme (G2P) converter. Our model has been trained with phonetically balanced 20 hours of single speaker speech data. It has obtained a 3.79 Mean Opinion Score (MOS) on a scale of 5.0 as subjective evaluation and a 0.77 Perceptual Evaluation of Speech Quality(PESQ) score on a scale of [-0.5, 4.5] as objective evaluation. It is outperforming all existing non-commercial state-of-the-art Bangla TTS systems based on naturalness.
On Stacked Denoising Autoencoder based Pre-training of ANN for Isolated Handwritten Bengali Numerals Dataset Recognition
Dec 14, 2018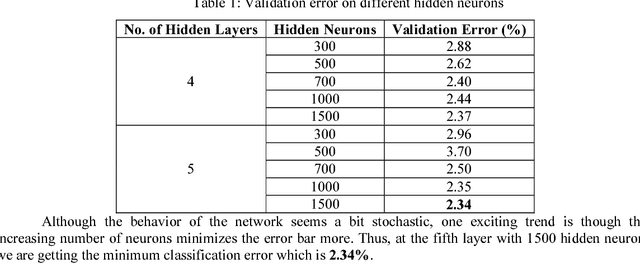
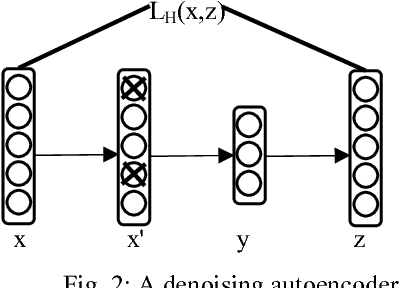

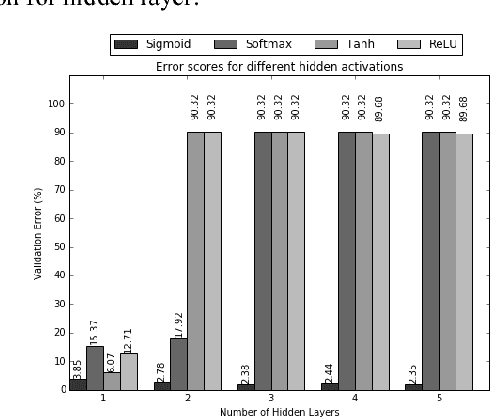
This work attempts to find the most optimal parameter setting of a deep artificial neural network (ANN) for Bengali digit dataset by pre-training it using stacked denoising autoencoder (SDA). Although SDA based recognition is hugely popular in image, speech and language processing related tasks among the researchers, it was never tried in Bengali dataset recognition. For this work, a dataset of 70000 handwritten samples were used from (Chowdhury and Rahman, 2016) and was recognized using several settings of network architecture. Among all these settings, the most optimal setting being found to be five or more deeper hidden layers with sigmoid activation and one output layer with softmax activation. We proposed the optimal number of neurons that can be used in the hidden layer is 1500 or more. The minimum validation error found from this work is 2.34% which is the lowest error rate on handwritten Bengali dataset proposed till date.