 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlant Leaf Disease Detection and Classification Using Deep Learning: A Review and A Proposed System on Bangladesh's Perspective
Jan 06, 2025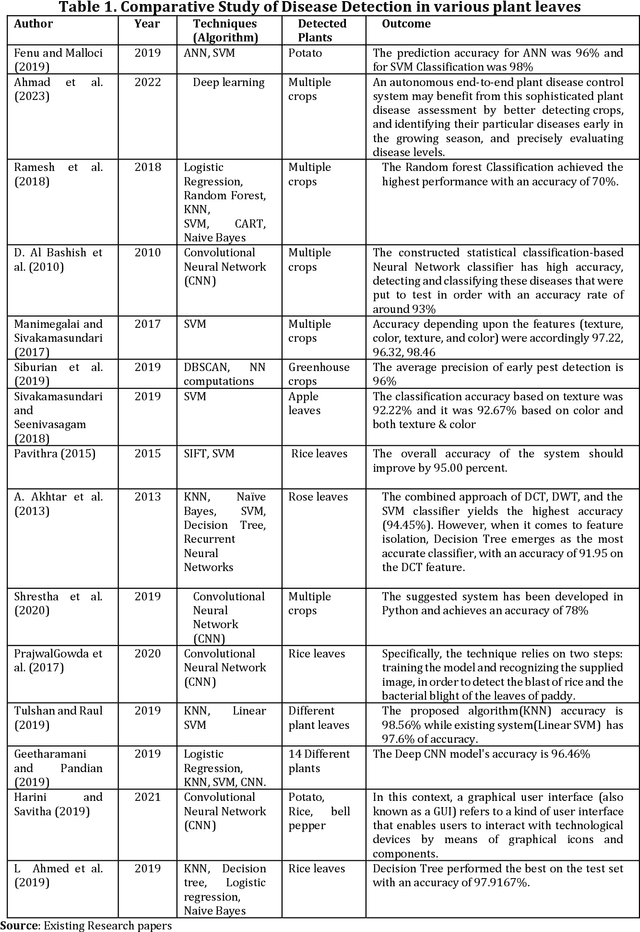
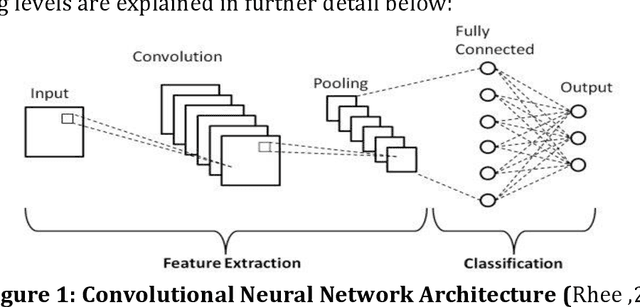

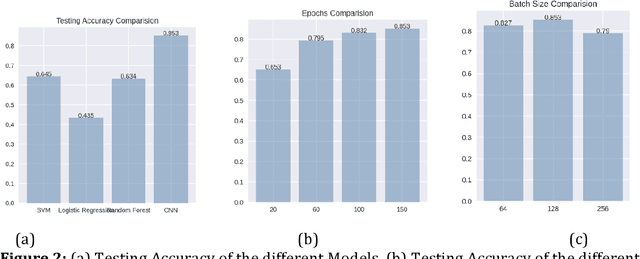
A very crucial part of Bangladeshi people's employment, GDP contribution, and mainly livelihood is agriculture. It plays a vital role in decreasing poverty and ensuring food security. Plant diseases are a serious stumbling block in agricultural production in Bangladesh. At times, humans can't detect the disease from an infected leaf with the naked eye. Using inorganic chemicals or pesticides in plants when it's too late leads in vain most of the time, deposing all the previous labor. The deep-learning technique of leaf-based image classification, which has shown impressive results, can make the work of recognizing and classifying all diseases trouble-less and more precise. In this paper, we've mainly proposed a better model for the detection of leaf diseases. Our proposed paper includes the collection of data on three different kinds of crops: bell peppers, tomatoes, and potatoes. For training and testing the proposed CNN model, the plant leaf disease dataset collected from Kaggle is used, which has 17,430 images. The images are labeled with 14 separate classes of damage. The developed CNN model performs efficiently and could successfully detect and classify the tested diseases. The proposed CNN model may have great potency in crop disease management.
Investigating the effect of domain selection on automatic speech recognition performance: a case study on Bangladeshi Bangla
Oct 24, 2022The performance of data-driven natural language processing systems is contingent upon the quality of corpora. However, principal corpus design criteria are often not identified and examined adequately, particularly in the speech processing discipline. Speech corpora development requires additional attention with regard to clean/noisy, read/spontaneous, multi-talker speech, accents/dialects, etc. Domain selection is also a crucial decision point in speech corpus development. In this study, we demonstrate the significance of domain selection by assessing a state-of-the-art Bangla automatic speech recognition (ASR) model on a novel multi-domain Bangladeshi Bangla ASR evaluation benchmark - BanSpeech, which contains 7.2 hours of speech and 9802 utterances from 19 distinct domains. The ASR model has been trained with deep convolutional neural network (CNN), layer normalization technique, and Connectionist Temporal Classification (CTC) loss criterion on SUBAK.KO, a mostly read speech corpus for the low-resource and morphologically rich language Bangla. Experimental evaluation reveals the ASR model on SUBAK.KO faces difficulty recognizing speech from domains with mostly spontaneous speech and has a high number of out-of-vocabulary (OOV) words. The same ASR model, on the other hand, performs better in read speech domains and contains fewer OOV words. In addition, we report the outcomes of our experiments with layer normalization, input feature extraction, number of convolutional layers, etc., and set a baseline on SUBAK.KO. The BanSpeech will be publicly available to meet the need for a challenging evaluation benchmark for Bangla ASR.