 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Stacked Denoising Autoencoder based Pre-training of ANN for Isolated Handwritten Bengali Numerals Dataset Recognition
Paper and Code
Dec 14, 2018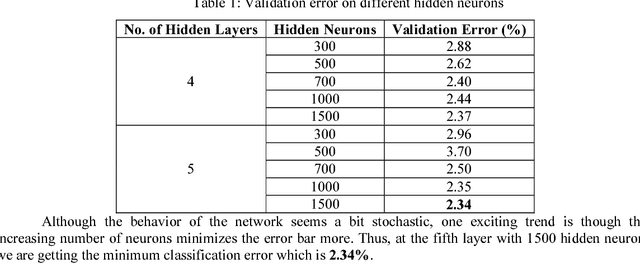
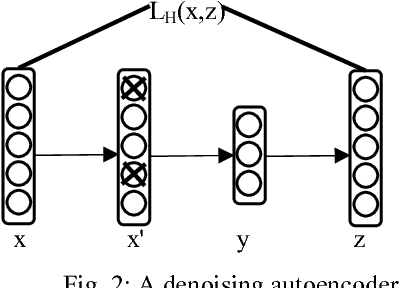

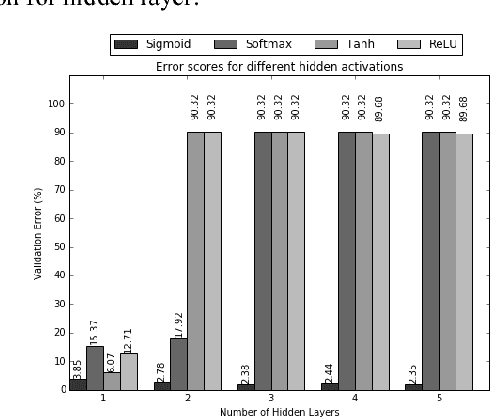
This work attempts to find the most optimal parameter setting of a deep artificial neural network (ANN) for Bengali digit dataset by pre-training it using stacked denoising autoencoder (SDA). Although SDA based recognition is hugely popular in image, speech and language processing related tasks among the researchers, it was never tried in Bengali dataset recognition. For this work, a dataset of 70000 handwritten samples were used from (Chowdhury and Rahman, 2016) and was recognized using several settings of network architecture. Among all these settings, the most optimal setting being found to be five or more deeper hidden layers with sigmoid activation and one output layer with softmax activation. We proposed the optimal number of neurons that can be used in the hidden layer is 1500 or more. The minimum validation error found from this work is 2.34% which is the lowest error rate on handwritten Bengali dataset proposed till date.