 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Finite Difference Method for Deep Reinforcement Learning
Oct 14, 2022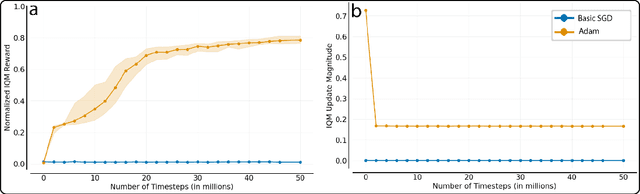


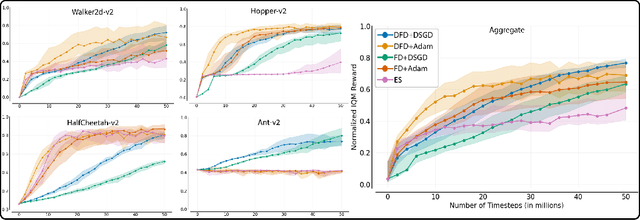
Several low-bandwidth distributable black-box optimization algorithms have recently been shown to perform nearly as well as more refined modern methods in some Deep Reinforcement Learning domains. In this work we investigate a core problem with the use of distributed workers in such systems. Further, we investigate the dramatic differences in performance between the popular Adam gradient descent algorithm and the simplest form of stochastic gradient descent. These investigations produce a stable, low-bandwidth learning algorithm that achieves 100\% usage of all connected CPUs under typical conditions.
Provenance-Based Interpretation of Multi-Agent Information Analysis
Nov 08, 2020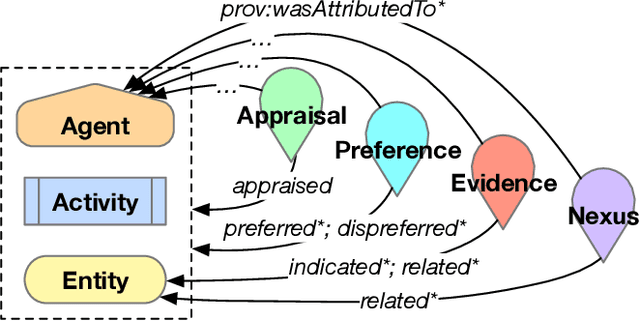
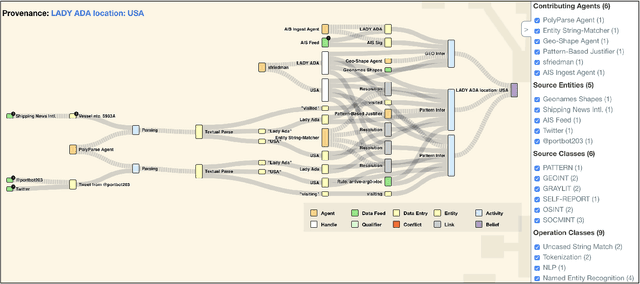
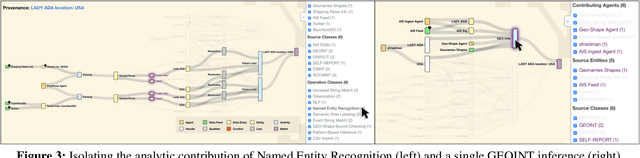
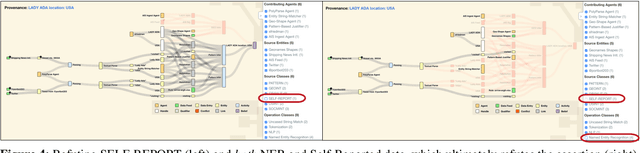
Analytic software tools and workflows are increasing in capability, complexity, number, and scale, and the integrity of our workflows is as important as ever. Specifically, we must be able to inspect the process of analytic workflows to assess (1) confidence of the conclusions, (2) risks and biases of the operations involved, (3) sensitivity of the conclusions to sources and agents, (4) impact and pertinence of various sources and agents, and (5) diversity of the sources that support the conclusions. We present an approach that tracks agents' provenance with PROV-O in conjunction with agents' appraisals and evidence links (expressed in our novel DIVE ontology). Together, PROV-O and DIVE enable dynamic propagation of confidence and counter-factual refutation to improve human-machine trust and analytic integrity. We demonstrate representative software developed for user interaction with that provenance, and discuss key needs for organizations adopting such approaches. We demonstrate all of these assessments in a multi-agent analysis scenario, using an interactive web-based information validation UI.
* 6 pages, 5 figures, appears in Proceedings of TaPP 2020
Evolution Strategies Converges to Finite Differences
Dec 27, 2019Since the debut of Evolution Strategies (ES) as a tool for Reinforcement Learning by Salimans et al. 2017, there has been interest in determining the exact relationship between the Evolution Strategies gradient and the gradient of a similar class of algorithms, Finite Differences (FD).(Zhang et al. 2017, Lehman et al. 2018) Several investigations into the subject have been performed, investigating the formal motivational differences(Lehman et al. 2018) between ES and FD, as well as the differences in a standard benchmark problem in Machine Learning, the MNIST classification problem(Zhang et al. 2017). This paper proves that while the gradients are different, they converge as the dimension of the vector under optimization increases.