Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Finite Difference Method for Deep Reinforcement Learning
Oct 14, 2022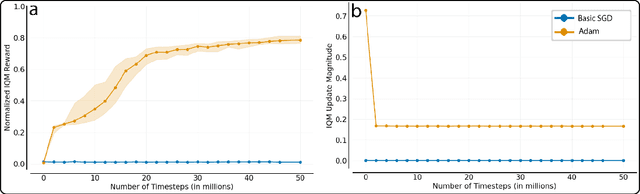


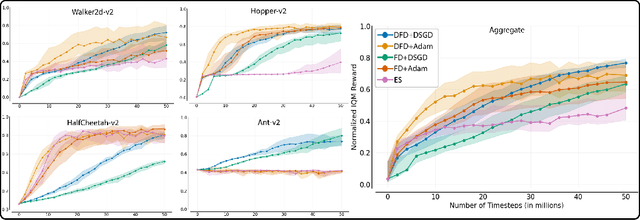
Several low-bandwidth distributable black-box optimization algorithms have recently been shown to perform nearly as well as more refined modern methods in some Deep Reinforcement Learning domains. In this work we investigate a core problem with the use of distributed workers in such systems. Further, we investigate the dramatic differences in performance between the popular Adam gradient descent algorithm and the simplest form of stochastic gradient descent. These investigations produce a stable, low-bandwidth learning algorithm that achieves 100\% usage of all connected CPUs under typical conditions.
Via