 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting the User-Item Graph with Textual Similarity Models
Sep 20, 2021

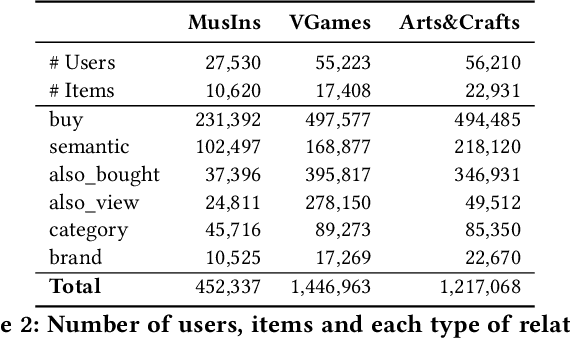
This paper introduces a simple and effective form of data augmentation for recommender systems. A paraphrase similarity model is applied to widely available textual data, such as reviews and product descriptions, yielding new semantic relations that are added to the user-item graph. This increases the density of the graph without needing further labeled data. The data augmentation is evaluated on a variety of recommendation algorithms, using Euclidean, hyperbolic, and complex spaces, and over three categories of Amazon product reviews with differing characteristics. Results show that the data augmentation technique provides significant improvements to all types of models, with the most pronounced gains for knowledge graph-based recommenders, particularly in cold-start settings, leading to state-of-the-art performance.