 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexMTrans: Temporal Attentive Cross-Modality Fusion Transformer for Long-Term Traffic Prediction
May 08, 2024Traffic predictions play a crucial role in intelligent transportation systems. The rapid development of IoT devices allows us to collect different kinds of data with high correlations to traffic predictions, fostering the development of efficient multi-modal traffic prediction models. Until now, there are few studies focusing on utilizing advantages of multi-modal data for traffic predictions. In this paper, we introduce a novel temporal attentive cross-modality transformer model for long-term traffic predictions, namely xMTrans, with capability of exploring the temporal correlations between the data of two modalities: one target modality (for prediction, e.g., traffic congestion) and one support modality (e.g., people flow). We conducted extensive experiments to evaluate our proposed model on traffic congestion and taxi demand predictions using real-world datasets. The results showed the superiority of xMTrans against recent state-of-the-art methods on long-term traffic predictions. In addition, we also conducted a comprehensive ablation study to further analyze the effectiveness of each module in xMTrans.
A Transformer-based Math Language Model for Handwritten Math Expression Recognition
Aug 11, 2021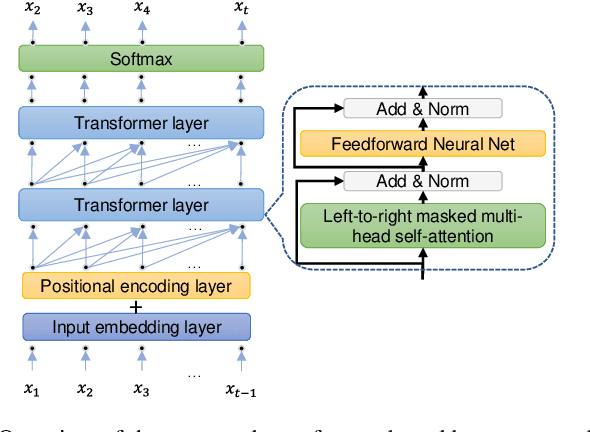
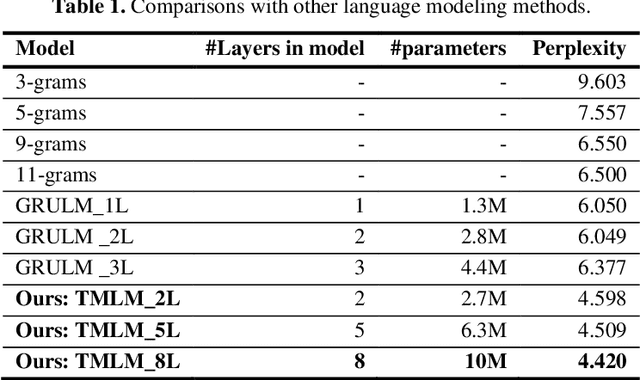
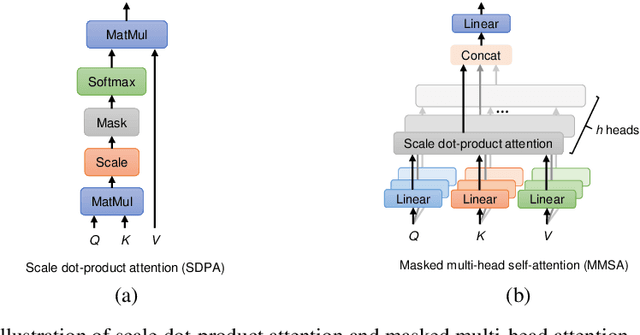

Handwritten mathematical expressions (HMEs) contain ambiguities in their interpretations, even for humans sometimes. Several math symbols are very similar in the writing style, such as dot and comma or 0, O, and o, which is a challenge for HME recognition systems to handle without using contextual information. To address this problem, this paper presents a Transformer-based Math Language Model (TMLM). Based on the self-attention mechanism, the high-level representation of an input token in a sequence of tokens is computed by how it is related to the previous tokens. Thus, TMLM can capture long dependencies and correlations among symbols and relations in a mathematical expression (ME). We trained the proposed language model using a corpus of approximately 70,000 LaTeX sequences provided in CROHME 2016. TMLM achieved the perplexity of 4.42, which outperformed the previous math language models, i.e., the N-gram and recurrent neural network-based language models. In addition, we combine TMLM into a stochastic context-free grammar-based HME recognition system using a weighting parameter to re-rank the top-10 best candidates. The expression rates on the testing sets of CROHME 2016 and CROHME 2019 were improved by 2.97 and 0.83 percentage points, respectively.
GSSF: A Generative Sequence Similarity Function based on a Seq2Seq model for clustering online handwritten mathematical answers
May 21, 2021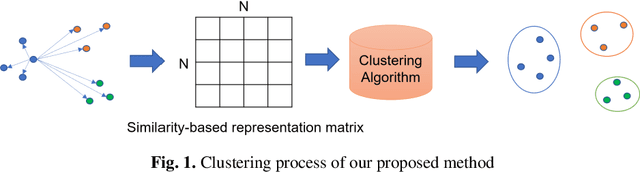
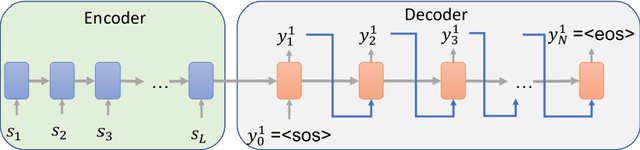
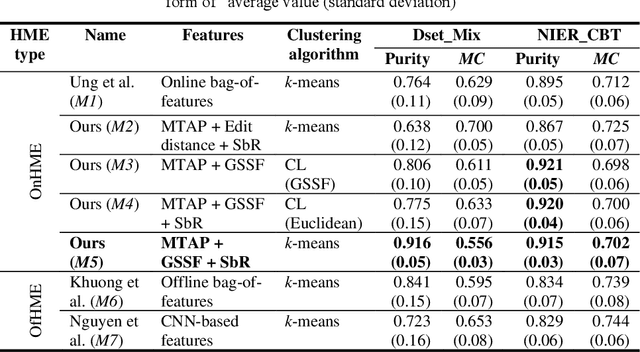
Toward a computer-assisted marking for descriptive math questions,this paper presents clustering of online handwritten mathematical expressions (OnHMEs) to help human markers to mark them efficiently and reliably. We propose a generative sequence similarity function for computing a similarity score of two OnHMEs based on a sequence-to-sequence OnHME recognizer. Each OnHME is represented by a similarity-based representation (SbR) vector. The SbR matrix is inputted to the k-means algorithm for clustering OnHMEs. Experiments are conducted on an answer dataset (Dset_Mix) of 200 OnHMEs mixed of real patterns and synthesized patterns for each of 10 questions and a real online handwritten mathematical answer dataset of 122 student answers at most for each of 15 questions (NIER_CBT). The best clustering results achieved around 0.916 and 0.915 for purity, and around 0.556 and 0.702 for the marking cost on Dset_Mix and NIER_CBT, respectively. Our method currently outperforms the previous methods for clustering HMEs.