 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexMTrans: Temporal Attentive Cross-Modality Fusion Transformer for Long-Term Traffic Prediction
May 08, 2024Traffic predictions play a crucial role in intelligent transportation systems. The rapid development of IoT devices allows us to collect different kinds of data with high correlations to traffic predictions, fostering the development of efficient multi-modal traffic prediction models. Until now, there are few studies focusing on utilizing advantages of multi-modal data for traffic predictions. In this paper, we introduce a novel temporal attentive cross-modality transformer model for long-term traffic predictions, namely xMTrans, with capability of exploring the temporal correlations between the data of two modalities: one target modality (for prediction, e.g., traffic congestion) and one support modality (e.g., people flow). We conducted extensive experiments to evaluate our proposed model on traffic congestion and taxi demand predictions using real-world datasets. The results showed the superiority of xMTrans against recent state-of-the-art methods on long-term traffic predictions. In addition, we also conducted a comprehensive ablation study to further analyze the effectiveness of each module in xMTrans.
VideoAdviser: Video Knowledge Distillation for Multimodal Transfer Learning
Sep 27, 2023Multimodal transfer learning aims to transform pretrained representations of diverse modalities into a common domain space for effective multimodal fusion. However, conventional systems are typically built on the assumption that all modalities exist, and the lack of modalities always leads to poor inference performance. Furthermore, extracting pretrained embeddings for all modalities is computationally inefficient for inference. In this work, to achieve high efficiency-performance multimodal transfer learning, we propose VideoAdviser, a video knowledge distillation method to transfer multimodal knowledge of video-enhanced prompts from a multimodal fundamental model (teacher) to a specific modal fundamental model (student). With an intuition that the best learning performance comes with professional advisers and smart students, we use a CLIP-based teacher model to provide expressive multimodal knowledge supervision signals to a RoBERTa-based student model via optimizing a step-distillation objective loss -- first step: the teacher distills multimodal knowledge of video-enhanced prompts from classification logits to a regression logit -- second step: the multimodal knowledge is distilled from the regression logit of the teacher to the student. We evaluate our method in two challenging multimodal tasks: video-level sentiment analysis (MOSI and MOSEI datasets) and audio-visual retrieval (VEGAS dataset). The student (requiring only the text modality as input) achieves an MAE score improvement of up to 12.3% for MOSI and MOSEI. Our method further enhances the state-of-the-art method by 3.4% mAP score for VEGAS without additional computations for inference. These results suggest the strengths of our method for achieving high efficiency-performance multimodal transfer learning.
* Accepted by IEEE Access
VQA-GNN: Reasoning with Multimodal Semantic Graph for Visual Question Answering
May 23, 2022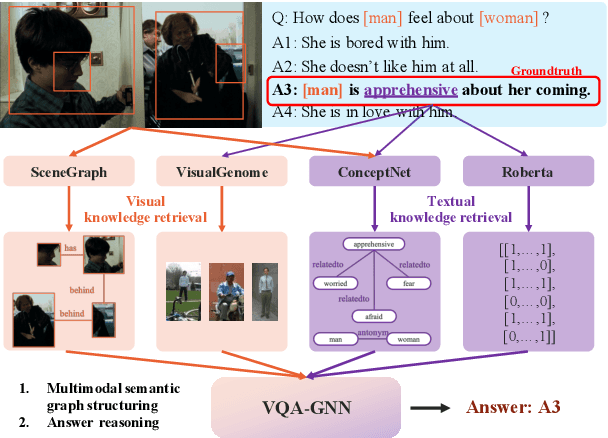
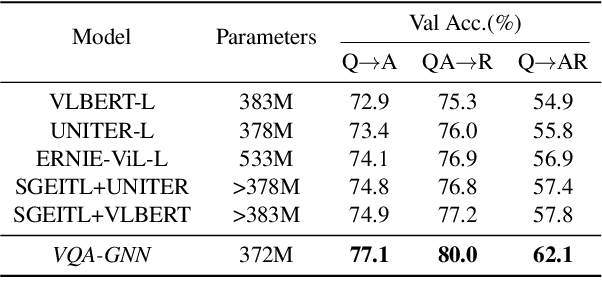
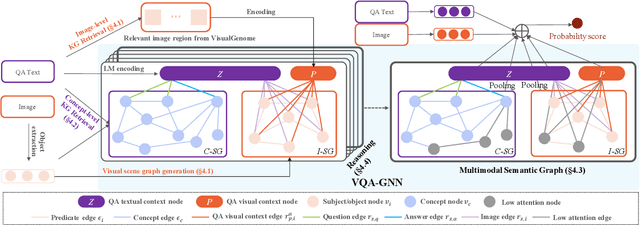

Visual understanding requires seamless integration between recognition and reasoning: beyond image-level recognition (e.g., detecting objects), systems must perform concept-level reasoning (e.g., inferring the context of objects and intents of people). However, existing methods only model the image-level features, and do not ground them and reason with background concepts such as knowledge graphs (KGs). In this work, we propose a novel visual question answering method, VQA-GNN, which unifies the image-level information and conceptual knowledge to perform joint reasoning of the scene. Specifically, given a question-image pair, we build a scene graph from the image, retrieve a relevant linguistic subgraph from ConceptNet and visual subgraph from VisualGenome, and unify these three graphs and the question into one joint graph, multimodal semantic graph. Our VQA-GNN then learns to aggregate messages and reason across different modalities captured by the multimodal semantic graph. In the evaluation on the VCR task, our method outperforms the previous scene graph-based Trans-VL models by over 4%, and VQA-GNN-Large, our model that fuses a Trans-VL further improves the state of the art by 2%, attaining the top of the VCR leaderboard at the time of submission. This result suggests the efficacy of our model in performing conceptual reasoning beyond image-level recognition for visual understanding. Finally, we demonstrate that our model is the first work to provide interpretability across visual and textual knowledge domains for the VQA task.