 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA-GNN: Reasoning with Multimodal Semantic Graph for Visual Question Answering
Paper and Code
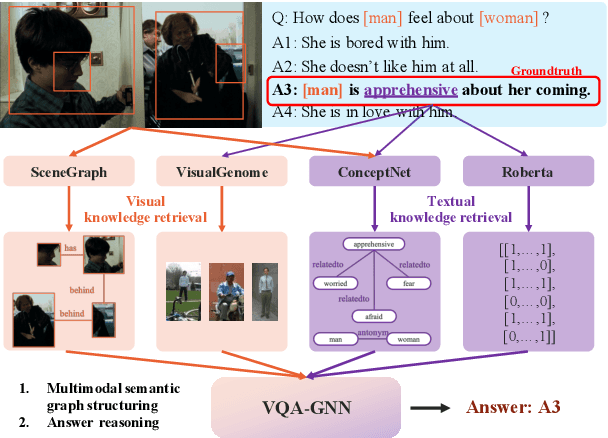
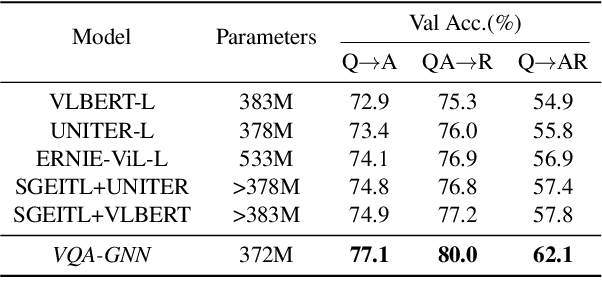
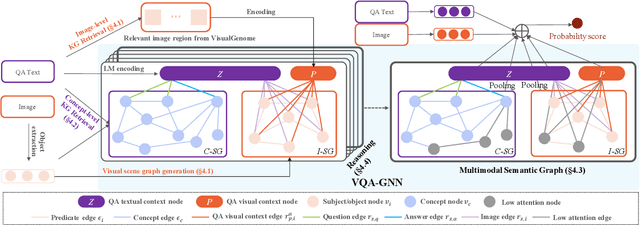

Visual understanding requires seamless integration between recognition and reasoning: beyond image-level recognition (e.g., detecting objects), systems must perform concept-level reasoning (e.g., inferring the context of objects and intents of people). However, existing methods only model the image-level features, and do not ground them and reason with background concepts such as knowledge graphs (KGs). In this work, we propose a novel visual question answering method, VQA-GNN, which unifies the image-level information and conceptual knowledge to perform joint reasoning of the scene. Specifically, given a question-image pair, we build a scene graph from the image, retrieve a relevant linguistic subgraph from ConceptNet and visual subgraph from VisualGenome, and unify these three graphs and the question into one joint graph, multimodal semantic graph. Our VQA-GNN then learns to aggregate messages and reason across different modalities captured by the multimodal semantic graph. In the evaluation on the VCR task, our method outperforms the previous scene graph-based Trans-VL models by over 4%, and VQA-GNN-Large, our model that fuses a Trans-VL further improves the state of the art by 2%, attaining the top of the VCR leaderboard at the time of submission. This result suggests the efficacy of our model in performing conceptual reasoning beyond image-level recognition for visual understanding. Finally, we demonstrate that our model is the first work to provide interpretability across visual and textual knowledge domains for the VQA task.