 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Machine Learning for Flood Detection in News, Social Media and Satellite Sequences
Oct 07, 2019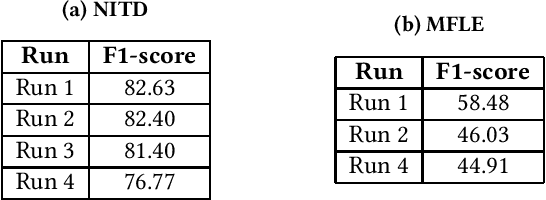
In this paper we present our methods for the MediaEval 2019 Mul-timedia Satellite Task, which is aiming to extract complementaryinformation associated with adverse events from Social Media andsatellites. For the first challenge, we propose a framework jointly uti-lizing colour, object and scene-level information to predict whetherthe topic of an article containing an image is a flood event or not.Visual features are combined using early and late fusion techniquesachieving an average F1-score of82.63,82.40,81.40and76.77. Forthe multi-modal flood level estimation, we rely on both visualand textual information achieving an average F1-score of58.48and46.03, respectively. Finally, for the flooding detection in time-based satellite image sequences we used a combination of classicalcomputer-vision and machine learning approaches achieving anaverage F1-score of58.82%
Top-Down Saliency Detection Driven by Visual Classification
Mar 23, 2018


This paper presents an approach for top-down saliency detection guided by visual classification tasks. We first learn how to compute visual saliency when a specific visual task has to be accomplished, as opposed to most state-of-the-art methods which assess saliency merely through bottom-up principles. Afterwards, we investigate if and to what extent visual saliency can support visual classification in nontrivial cases. To achieve this, we propose SalClassNet, a CNN framework consisting of two networks jointly trained: a) the first one computing top-down saliency maps from input images, and b) the second one exploiting the computed saliency maps for visual classification. To test our approach, we collected a dataset of eye-gaze maps, using a Tobii T60 eye tracker, by asking several subjects to look at images from the Stanford Dogs dataset, with the objective of distinguishing dog breeds. Performance analysis on our dataset and other saliency bench-marking datasets, such as POET, showed that SalClassNet out-performs state-of-the-art saliency detectors, such as SalNet and SALICON. Finally, we analyzed the performance of SalClassNet in a fine-grained recognition task and found out that it generalizes better than existing visual classifiers. The achieved results, thus, demonstrate that 1) conditioning saliency detectors with object classes reaches state-of-the-art performance, and 2) providing explicitly top-down saliency maps to visual classifiers enhances classification accuracy.